C/C++笔记
数组指针&指针的数组&数组名
故事从int (*)[10]开始,这是一种数据类型,具体点是一种“指向‘长度为10的int数组’这种类型的指针”类型。1
2
3
4
5
6
7
8
9
10
11
12
13int a[5] = {1,2,3,4,5};
int (*)[5] p1; //竟然是错误的用法。。。
int (*p2)[5] = a; //正不正确看编译器的种类和版本,不建议这么用
int (*p3)[5] = &a; //最正确的用法,注意,这里对a取地址得到的不是a的地址,而是将a的值直接赋过去,看起来就像没有取地址
/* 推荐用法 */
typedef uint8 Dt_ARRAY_700_uint8[700]; //先将数组定义成数据类型
Dt_ARRAY_700_uint8 uss_raw_data;
Dt_ARRAY_700_uint8 *ptr = &uss_raw_data; //正确用法
Dt_ARRAY_700_uint8 *ptr = uss_raw_data; //等价于上面p2那个不建议使用的用法,在qnx平台上编译时就报错了。
终结字符串、字符的数组、字符数组名
- 常规的char的数组
1
2
3
4
5/* 基于C99标准 */
char s1[5] = {'1', '2', '3', '4', '5'}; //常规的数组,只不过数组的元素是char
char s2[ ] = {'1', '2', '3', '4', '5'}; //效果同s1,生成一个长度为5的数组
char s3[6] = {'1', '2', '3', '4', '5'}; //s[6]未提供初始值,默认初始化为'\0'
char s4[7] = {'1', '2', '3', '4', '5'}; //原理同s3,s[6]和s[7]都被初始化为'\0' 基于”char的数组”实现的字符串语法糖
1
2
3
4
5/* 基于C99标准 */
char s5[ ] = "12345"; //自动开辟6个Byte而不是5个,s[5]默认初始化为'\0',最终效果同s3
char s6[6] = "12345"; //效果同s3和s5
char s7[5] = "12345"; //效果同s1和s2
char s8[7] = "12345"; //效果同s4基于”char的指针”实现的字符串语法糖
1
2/* 基于C99标准 */
char* s9 = "12345"; //自动开辟6个Byte而不是5个,s[5]默认初始化为'\0',最终效果同s3。但是,是在全局的只读数据区开辟,数组内容无法被修改。总结
当你想创建一个内存内容为{'1', '2', '3', '4', '5','\0'}的对象时,以下4种做法等价,正规来讲应该用s3,但最省事的肯定是s5和s9(所以说是两个语法糖)。然后再视是否需要修改对象内容来决定s5还是s9。1
2
3
4char s3[6] = {'1', '2', '3', '4', '5'};
char s5[ ] = "12345";
char s6[6] = "12345";
char* s9 = "12345";不过,在C99下发现s1,s2,s7这三个不以
'\0'结尾的也可以用printf("%s", s)打印。。。不过,为了防止混淆,还是不要这么用。
cin的控制流转移逻辑
- 运行到
cin >> x时,控制转移到终端,等待输入; - 此时可以向cin流写入多个值(以空格或者tab切分),直到输入回车,从终端向cin流写入的过程停止,控制返回给程序。
- cin以分隔符将流内的内容喂给
>>右侧的变量 - 再>>时,会先检查流是否为空,不为空则无需变更控制流,按照上一条的逻辑继续写目标变量。
未命名的命名空间与静态声明
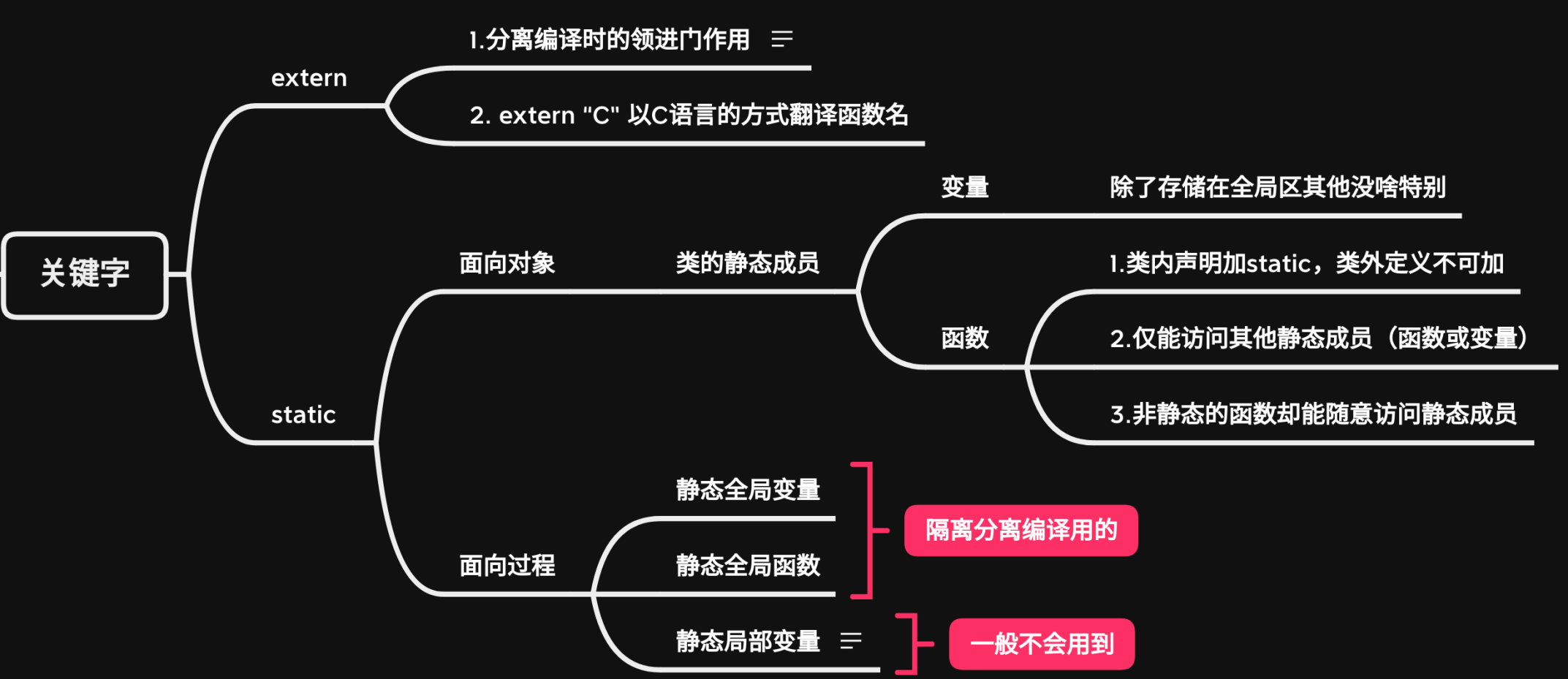
静态声明的使用方法分两大类,其中面向过程的使用方法已经被C++标准取消,相应的符号隔离机制通过未命名的命名空间来实现。
define的特殊符号
1 | |
unique_ptr的两种指针释放方式
- release
release只是简单的将被unique_ptr封装的内置指针吐出来,被指向的对象的内存不会被释放,内置指针与该对象之间的指向关系也不会被破坏。 - reset
reset首先释放unique_ptr封装起来的那个内置指针所指向的内存,然后根据传入的参数对该内置指针进行赋值。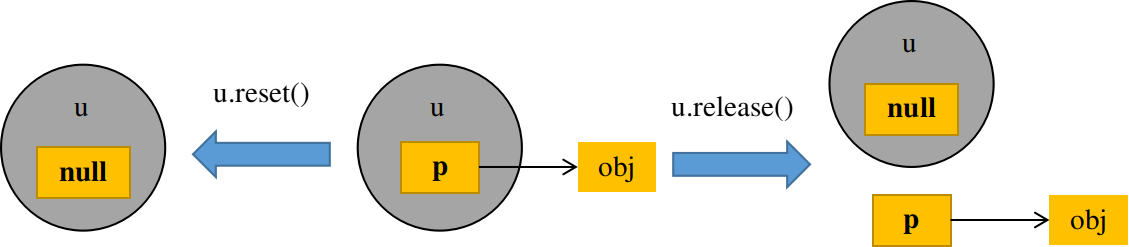
结构体排序
对于一串结构体,想排序,在C中可以基于stdlib库中的qsort接口配合一个自定义的比较函数实现。在C++中,有更elegant的做法。
首先,如果这个类重载了小于运算符,那么直接调用algorithm库中的sort函数即可进行升序排列;
其次,如果没有重载小于运算符,也可传入一个函数指针,或者就地定义一个lambda表达式。
最后说一下sort接口的语义:
在sort的过程,针对一对元素A和B,需要知道谁应该在前,谁应该在后。怎么判断呢?将A在前,B在后送入给到sort接口的函数(重载的小于运算符也好,函数指针也好,lambda表达式也好,都是),如果吐出来true,说明次序对,否则次序相反。1
2
3
4
5
6
7
8
9
10
11vector<Point> p = {····};
方式一:结构体重载了operator<
sort(v.begin(), v.end());
方式二:传入函数指针
bool compare(const Point& p1, const Point& p2) {return p1.x < p2.x;}
sort(v.begin(), v.end(), compare);
方式三:就地lambda表达式
sort(v.begin(), v.end(), [](const Point& p1, const Point& p2) {return p1.x < p2.x;});
另外还要提一点,就是STL中list容器的sort。algorithm提供的sort接口需要待排序结构体所在的容器提供随机访问迭代器,而list是不具备的。因此,list容器自己实现了sort成员函数。这个成员函数也是接受一个函数指针或者lambda表达式来check先后次序。
自定义数据结构如何使用范围for
1 | |
自定义的数据结构需要同时满足以下五个条件,就可以对其使用上述范围for语句对容器进行遍历:
- 定义了迭代器,指针也算;——用来迭代
- 定义了
begin()和end()方法;——用来启动和终止迭代 - 针对迭代器定义了
!=运算符;——用来进行终止条件判定 - 针对迭代器定义了
++前置自增运算符;——用来递增迭代器 - 针对迭代器定义了
*解引用操作符;——用来访问容器元素
0做除数
无论整型还是浮点型,只要是0以字面值的形式做除数,那么编译都会报错;1
2
3//以下两种形式均无法通过编译
std::cout << 1/0 << std::endl;
std::cout << 1/0.0 << std::endl;
但如果是以变量的形式做除数,那么编译可通过,运行是否抛出异常则要看变量的类型;
- 变量为整型,运行报错,
division by zero - 变量为浮点型,运行不报错,只是除法运算的结果为
inf1
2
3
4
5
6
7//编译不报错,运行报错
int a = 0;
std::cout << 1/a << std::endl;
//编译不报错,运行也不报错
double b = 0;
std::cout << 1/b << std::endl;
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!