AlexNet
背景简介
Hinton学生Alex之作,2012年的ISLVRC冠军,深度学习方法甩开传统图像算法的开端,GPU训练的开端。
网络结构
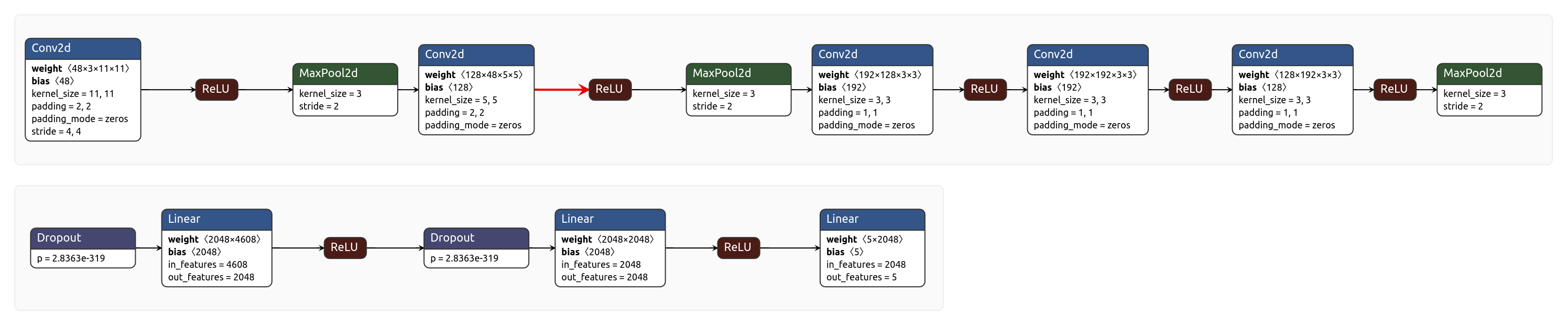
原始输入:尺寸为[224, 224, 3]的三通道RGB彩色图像
特征提取层:上图中的第一行,(conv, relu, max_pool)经典三元结构x2 + (conv, relu)经典二元结构x3 + max_pool
分类层:将特征提取层的结果flatten之后,接上2个FC层和1个softmax层,其中这两个FC层之前都用了dropout机制。
网络特点
- 首用RELU代替以往的sigmoid和tanh(后面补充上各种激活函数的详情文章链接)
- 首用LRN局部相应归一化(有时间这里展开讲一下,目前看不是很重要。。)
- 首用DROPOUT机制进行正则,具体的实现原理如下:
1
2d = np.random.rand( a.shape[1], a.shape[1] ) < keep_prob
a = a * d / keep_prob- 对于一个需要进行dropout的网络层,在获得这一层的激活值a之后,输入到下一层网络之前,用一个随机生成的dropout mask矩阵和a进行逐元素乘法。当然,两者形状一致。
- dropout mask矩阵一般是用rand函数产生的一个和a同尺寸的矩阵,每个元素的值为0-1之间的随机数。若某个元素小于keep_prob则得到1,大于则得到0。这解释了keep_prob的名称的由来,有比例为keep_prob的元素未被置0。
- 最后在将a输入到下一层之前,还要恢复a的数学期望,即代码中除以keep_prob的操作。这样就只需要在train过程考虑dropout,而在test时直接关闭dropout即可(对应pytorch中模型eval和train模式的设定)
其他内容
网络结构图中为了减少参数量,加快训练过程,所有网络层的尺寸都设为了原作的一半。这不是重点。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!