GoogLeNet
背景简介
2014年Google团队提出,当年的ImageNet分类任务第一名(第二名是VGG)。其中的Inception结构和辅助分类器的概念很有启发性和创造性。
网络结构
整体结构
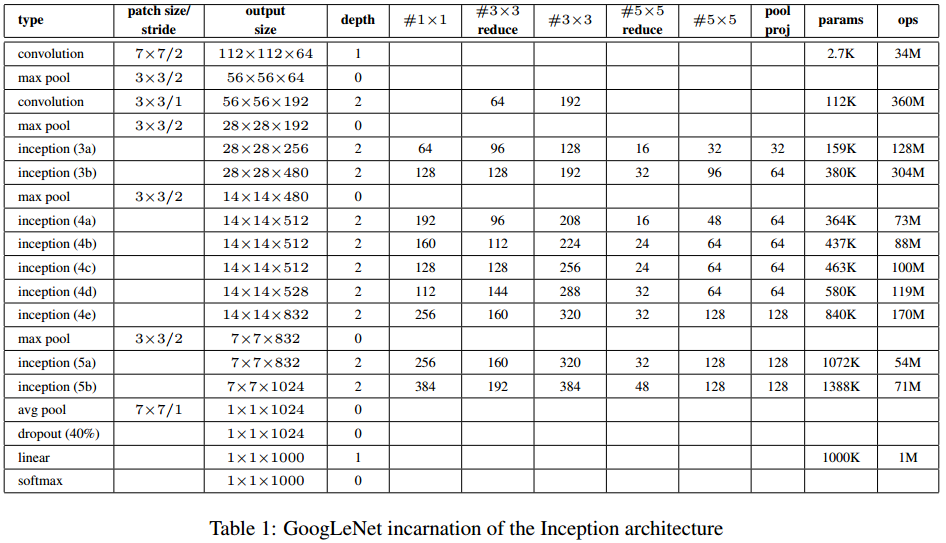
构建起整个网络的building blocks有5种:
- 常规的卷积层,默认以RELU为激活函数,SAME padding
- 常规的池化层,包括最大池化和平均池化
- Inception单元,共计3层9个,具体结构后面解释
- 辅助分类器2个,具体结构后面解释
- 最终输出的softmax FC层
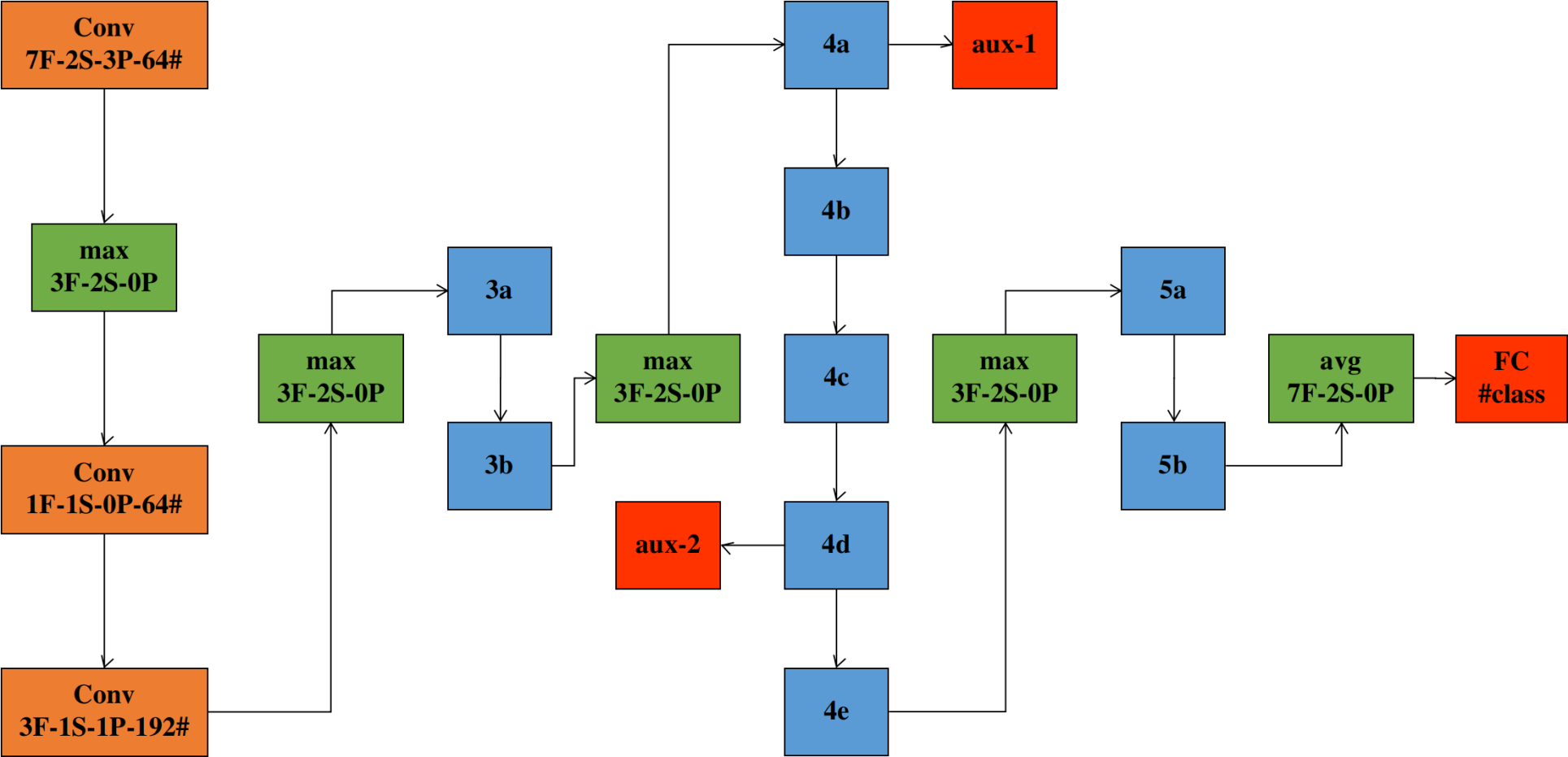
如上图所示,常规卷积层、池化层、softmax FC层的结构参数已标出。各个Inception单元的参数可参照下表得出,表头的解释详见这里。辅助分类器的结构是固定的,在后面会讲。
第一个maxpool之后,第二个maxpool之前还各有一个LRN操作,但据说用处不大,就省略了。
Inception单元
理解GoogLeNet的网络结构首先要理解Inception结构,整个GoogLeNet主要由若干个Inception单元的组合。
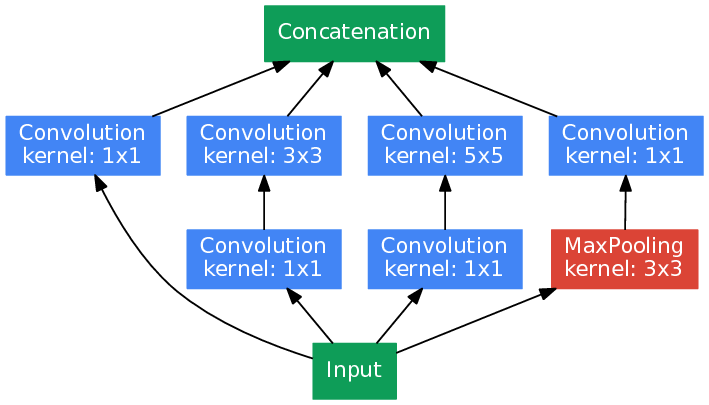
从上图可以看出,对于一个Inception单元而言,input通过4个并联的卷积运算分支产生4路输出。这4个分支的卷积核各不相同,意味着从input提取出不同尺度的特征,这使得训练出来的模型能够同时兼顾一副图像中不同尺度的特征。并且,4路输出的tensor的宽和高是相同的,因此可以将其沿着深度方向堆叠起来,形成整个Inception单元的输出。看下图更直观的说明了这个过程
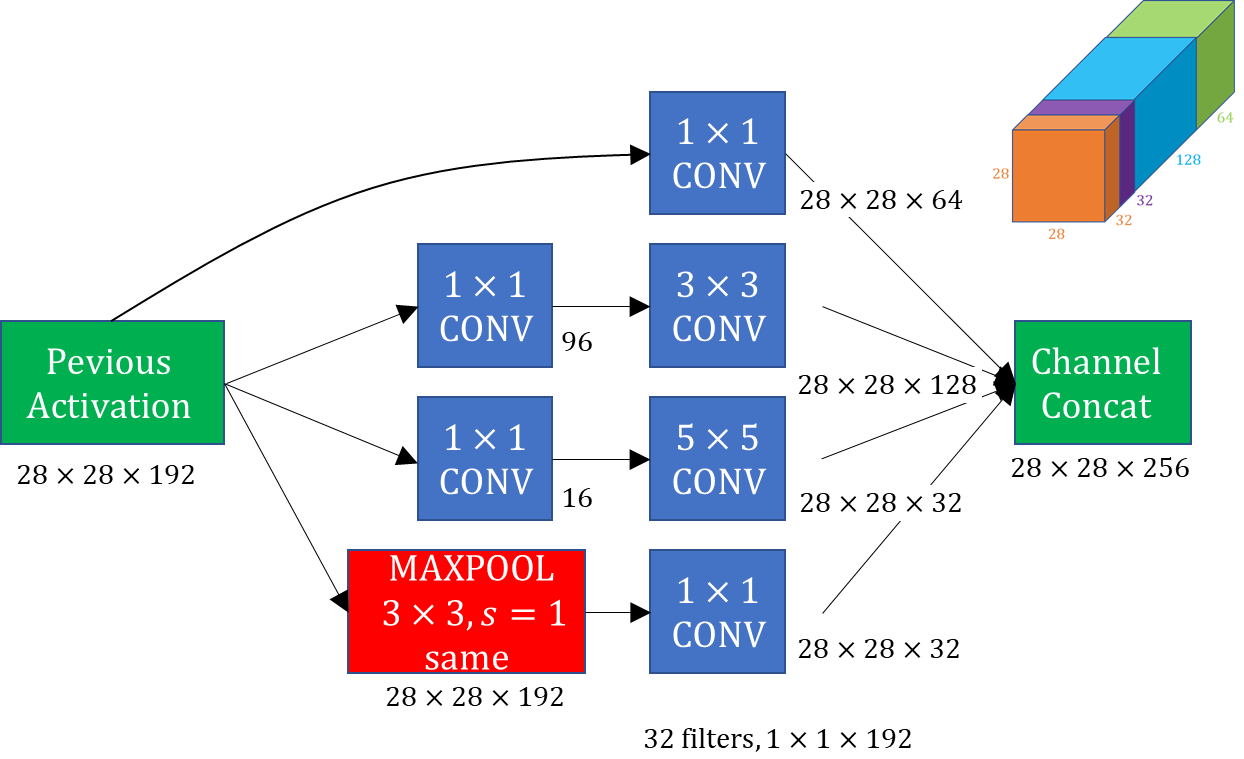
具体来看这4路分支:
- 1x1卷积,调整深度,宽和高相对于input不变。
- 1x1卷积 + 3x3卷积,其中会造成尺寸缩减的3x3卷积采用SAME padding,同样保持了尺寸。
- 1x1卷积 + 5x5卷积,其中会造成尺寸缩减的5x5卷积采用SAME padding,同样保持了尺寸。
- 3x3池化 + 1x1卷积,其中池化层做了SAME padding。——先后顺序为什么这么突出?mark
另外值得注意的是,在对于一个Inception单元而言,4个支路的卷积核数量一般是配置参数,而卷积核的尺寸是固定的。这意味着一个Inception单元的参数应该为上述6个卷积核的个数+本单元的输入的深度。
辅助分类器
另外一个特殊之处是,GoogLeNet在进行模型训练时(预测时没有)在中间层也进行了两次结果输出。
辅助分类器的结构
这两个辅助分类器的结构是相同的:

- 首先是一个5x5,s=3的平均池化
- 然后接一个1x1卷积层,卷积核数量128
- 然后展平、dropout、接第一个FC(激活函数为RELU)
- 然后在dropout,接第二个FC(激活函数为softmax)
第一层FC有1024个神经元,第二层为输出层,神经元数量取决于class_num。另外值得注意的是,两个辅助分类器的输入tensor的形状是相同的,只有深度不同,都是[batch, d, 4, 4]。经过相同的池化层处理后,形状继续保持一致。再经过相同的1x1卷积层处理后,深度也变为一致的。因此可以看出这里的1x1卷积层是为了rectify辅助分类器的输入,使其适配性更强。
对应的损失函数
1 | |
三个分类器的输出分别计算loss,然后加权之后的和作为整个模型的loss。
实现时的trick
由于最终的结果只看主分类器的,那么就带了两个问题:
- 训练过程的验证时不需要进行辅助分类器的计算,此时通过在模型的forward方法中借助
self.training设定即可。该属性在net.train()时为true,net.eval()时为false; - 实际部署时,不仅不需要辅助分类器的计算,连辅助分类器的结构都不需要。此时,首先通过设定一个额外的flag,在model class中不构建辅助分类器。然后还要解决保存训练时保存的权重文件比此时的网络结构的参数多的问题。这个通过在
model.load_state_dict(torch.load(PATH),strict=False)增加strict参数来实现。
其他内容
- Inception结构中的卷积层默认包含一个RELU。
- 池化层跟1x1卷积刚好相反,它不改变tensor的深度,只改变tensor的宽和高,因此两者可以组成tensor尺寸manipulation的一对基。
- tensor的堆叠在pytorch中用
torch.cat()实现。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!