MobileNet v1
背景简介
由Google团队于2017年提出,专注于移动端和嵌入式设备。采用Depthwise卷积,大幅减少参数量,虽然效果有一些折扣,但是可以接受。
前置知识
DW卷积
先来回忆以下常规的卷积是怎样的,如下图所示。
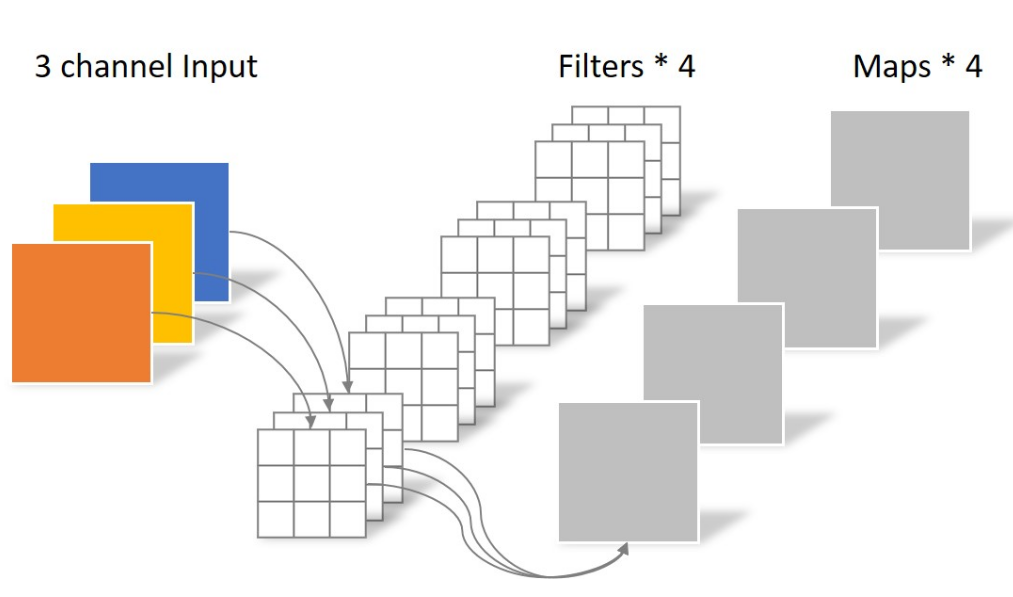
而DW卷积呢,其实就是最符合直觉的那种卷积。就是每个卷积核的深度不是和上一层输出相同,而是等于1。这意味着:
- 卷积之后不再做跨深度的求和
- 每一个DW卷积层的#参数必然等于输入tensor的深度,因为要保证输入tensor的每一个通道都有一个1层的卷积核去和它运算
- 经过DW卷积之后得到的输出,深度不变
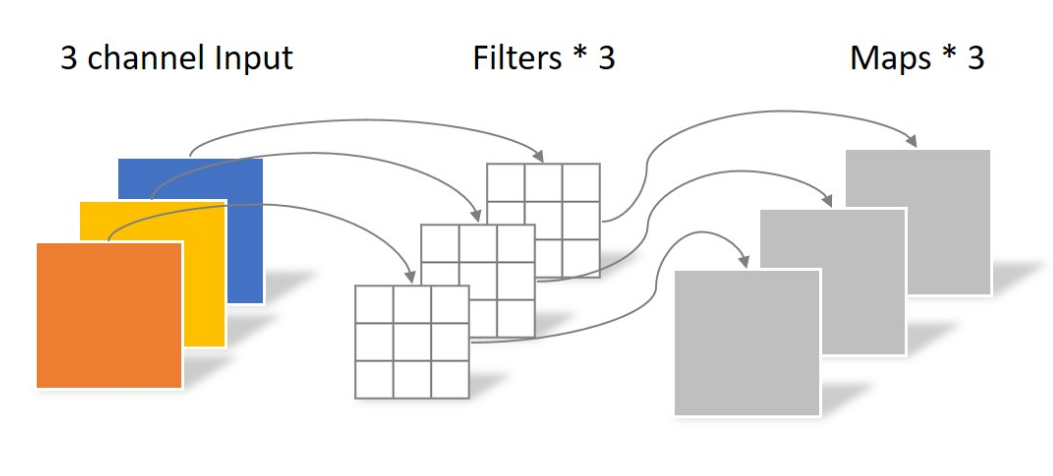
PW卷积
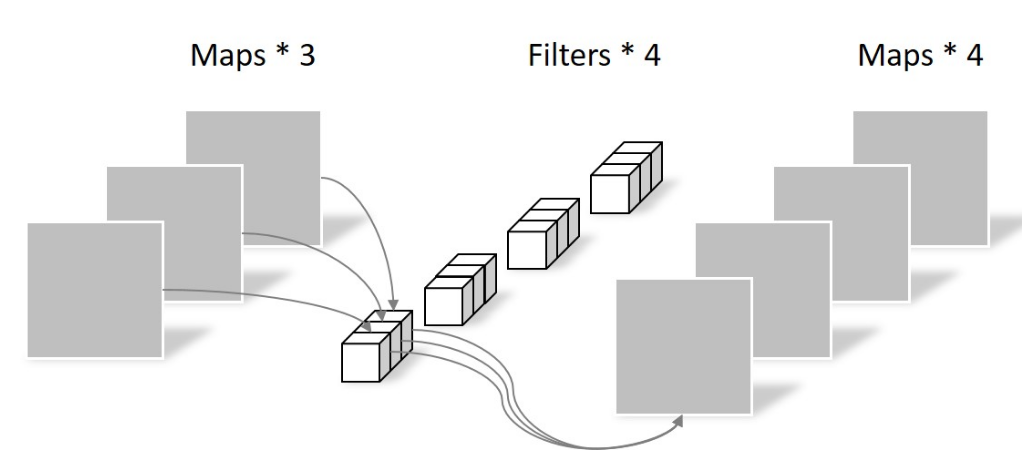
DW卷积一看就是个瘸腿儿的机制,搞来搞去没法manipulate tensor的深度啊,所以必须伴随这PW卷积使用。PW卷积就是常规1x1的卷积,它的特点是不改变tensor的尺寸,只改变tensor的深度。这么一来跟DW卷积就完美配合了——先对tensor进行DW卷积改变尺寸,然后进行PW卷积对DW的输出进行跨通道加权求和,每个PW卷积核得到一个2维的tensor,这样,通过设置不同的卷积核个数即可控制最终输出的通道数。
网络结构
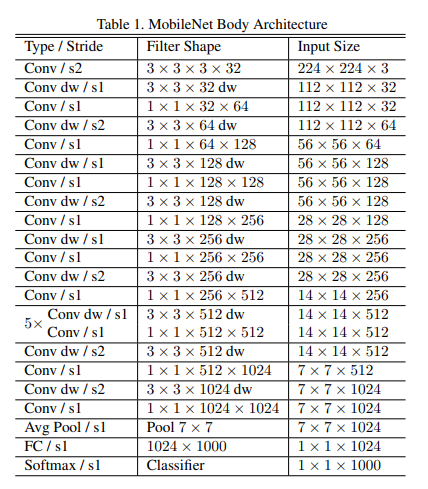
主要就是DW层和PW层的堆叠。另外,额外设有两个可调的超参数$\alpha$和$\beta$,前者是每一层的PW卷积核数量基于上表中数量的系数,后者是基于224x224的输入图像分辨率的系数。
其他内容
- 实际使用发现,经常有很多DW卷积核的元素值为0,造成浪费,原因后面再补充吧。mark
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!