关于交叉熵的易混淆概念
0. 前言
交叉熵,二值交叉熵,softmax,sigmoid等概念经常一起出现,这里结合pytorch的具体实现来捋清楚这几个概念。
1. 概念
1.1 交叉熵
交叉熵用于描述两个概率分布的差异,也就是说处理的都是0-1之间的数值。
在实际应用中,一般用于计算分类损失。并且,为了避免对0取对数,会将GT的one-hot向量作为$p$,预测结果作为$q$。
1.2 二值交叉熵
二值交叉熵就是上述交叉熵公式在$x$只有两个取值时的特例。
1.3 sigmoid函数
一般模型直接输出的结果向量不保证其中的标量元素的数值(pytorch等官方术语称logits)在0-1之间,因此要用到sigmoid这种值域在0-1之间的激活函数将每一个logit单独作映射,然后再进行交叉熵计算。
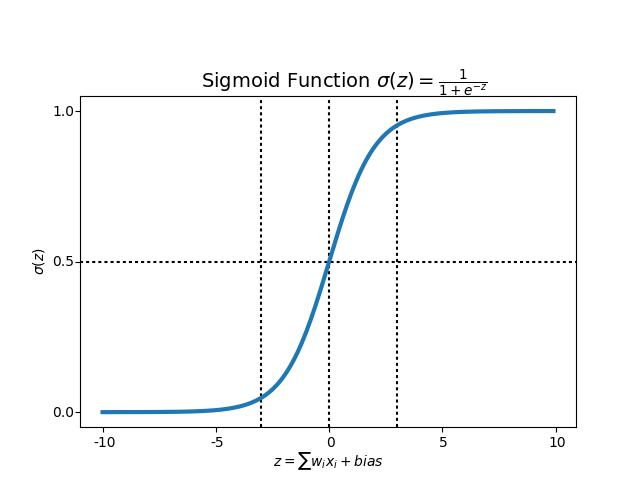
1.4 softmax函数
跟sigmoid一样,也是一个logit归一化的工具,但是需要所有logits一起做联合映射,而不是独立映射。
2. pytorch实现
pytorch中的nn模块和nn.funtional模块中都有交叉熵损失的实现,这里只介绍nn下的3个模块。
2.1 nn.CrossEntropyLoss
主要的入参有input(N, C)和target(N,)两个,N是结果向量有几个,C是类别数量。
input的每一行都是一个结果向量,包含C个类别的各自的logit,这是因为这个模块内部集成了softmax函数,在进行损失计算之前会先对input做0-1的映射。
target每一行是一个真实标签序号,值在[0, C-1]之间。在进行算是计算之前会将target的每一行拓展成一个one-hot向量,hot的位置就是这个真实标签序号。
然后用1.1中的公式逐行计算这N个结果向量与N个one-hot向量的交叉熵,最后求和或求算数平均值(默认求均值)。
2.2 nn.BCEWithLogitsLoss
主要的入参还是input(N, C)和target(N, C)两个,但是target的形状不同,其每一行都直接是GT的one-hot向量。
也同样集成了sigmoid函数,计算损失之前会先对input做0-1的映射。
然后逐行选中一个C维的结果行向量和一个C维的GT one-hot行向量,按照1.2中的公式计算得到C个标量,求均值即可得到这一行的loss。
最后求各行的loss均值即可得到最终的loss。
2.3 nn.BCELoss
未集成sigmoid的二值交叉熵计算模块,有要求入参input的标量元素值在0-1之间,所以一般不使用,直接使用2.2。
3. 附录

1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!