pytorch笔记
max() sum()等操作中指定dim的含义
1 | |
- 对于这个[2, 2, 2]的三维矩阵,三维意味着[]有三层,三个2表示每一层[]内有两个元素
- 对dim=0求max意味着
- 将与比较得出最大值作为
- 将与比较得出最大值作为…
- 对dim=1求max意味着
- 将与比较得出最大值作为
- 将与比较得出最大值作为…
- 而$a_{010}$对应于,第一层[]中的第一个元素的,第二个元素的,第一个元素
torch.flatten()中指定dim的含义
1 | |
torch.cat((x,y),d)中指定dim的含义
- 第一种解释,d=0就是按行堆叠x和y,堆叠后有了更多的行。然后是按列,按深度,以此类推。容易理解,适用于3维以下。
- 第二种解释,就是扩展x第d+1层[]中的内容,拿什么来扩展呢,拿y对应位置的元素,比较难理解,但适用性更广。
nn.MaxPool2d(3, stride=2, ceil_mode=True)中ceil_mode的含义
其实就是尺寸计算公式中是向上取整还是向下取整,默认向下取整,开了ceil_mode之后就向上取整。
nn.AvgPool2d(kernel_size=5, stride=3)与nn.AdaptiveAvgPool2d((1, 1))的区别
前者用指定的kernel_size和stride定义池化操作,后者则通过指定输出tensor的尺寸来定义池化操作,stride和kernel_size会自动算出来。
In average-pooling or max-pooling, you essentially set the stride and kernel-size by your own, setting them as hyper-parameters. You will have to re-configure them if you happen to change your input size.
In Adaptive Pooling on the other hand, we specify the output size instead. And the stride and kernel-size are automatically selected to adapt to the needs. The following equations are used to calculate the value in the source code.
2
3Stride = (input_size//output_size)
Kernel size = input_size - (output_size-1)*stride
Padding = 0
plt.imshow()与plt.show()的区别
plt.imshow()只是将图片与plt发生关联,但不显示,还可以继续对这张图片进行其他draw操作,最后再用plt.show()显示出来。
dataset dataset_loader dataset_loader_iter的区别
train_set不是Iterator,也不是Iterabel;train_loader不是Iterator,但是Iterable;- Iterable意味着可用于for循环被迭代, Iterator则是算法,不断用next产生需要的数据,Iterator必然Iterable
model的常用方法
一般一个model都是由一串nn.Module的派生类组合而成的class,而且其本身一般也是一个nn.Module的派生类。因为各个相关对象都来自一个公共基类,因此常用的成员函数也大致相同:
model.modules()&model.named_modules()model.children()&model.named_children()model.parameters()&model.named_parameters()model.buffers()&model.named_buffers()
这些方法都是返回一个generator,迭代它可以得到相应的元素。
其中,module和children返回的是一个nn.Module的派生类对象,不同点是前者递归式地返回model所有后代(而不只是叶子节点哦),后者返回其直接后代。
parameters返回的是一个Parameter对象,暂时可以理解为是一个tensor。
buffers返回的是一个tensor,保存过程数据running_mean、running_var等,具体含义暂时未知。一般只有作为叶子节点的module才有parameter和buffers。
另外就是带name的版本,相比与不带name的版本,迭代generator得到的是一个包含两个元素的tuple,第一个元素是name,第二个元素跟不带name的版本一样。
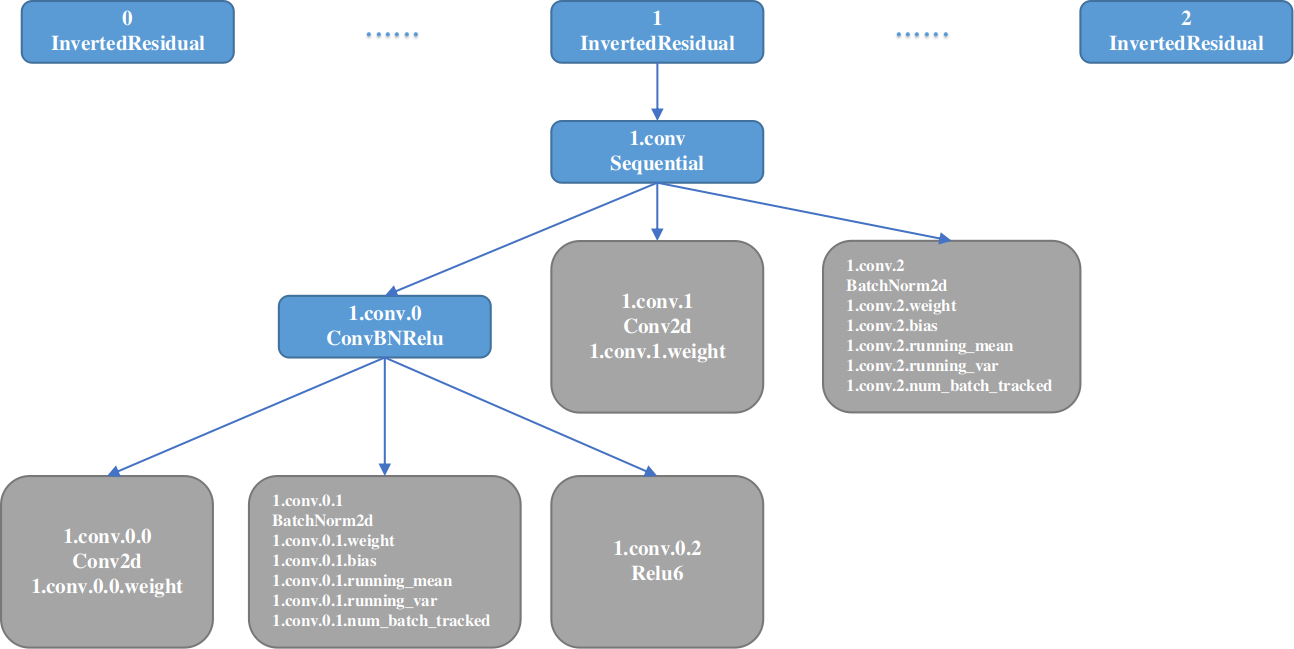
各个方法返回的元素的命名都是基于module的名称,以InvertedResidual模块为例,具体的命名逻辑如下图所示:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!