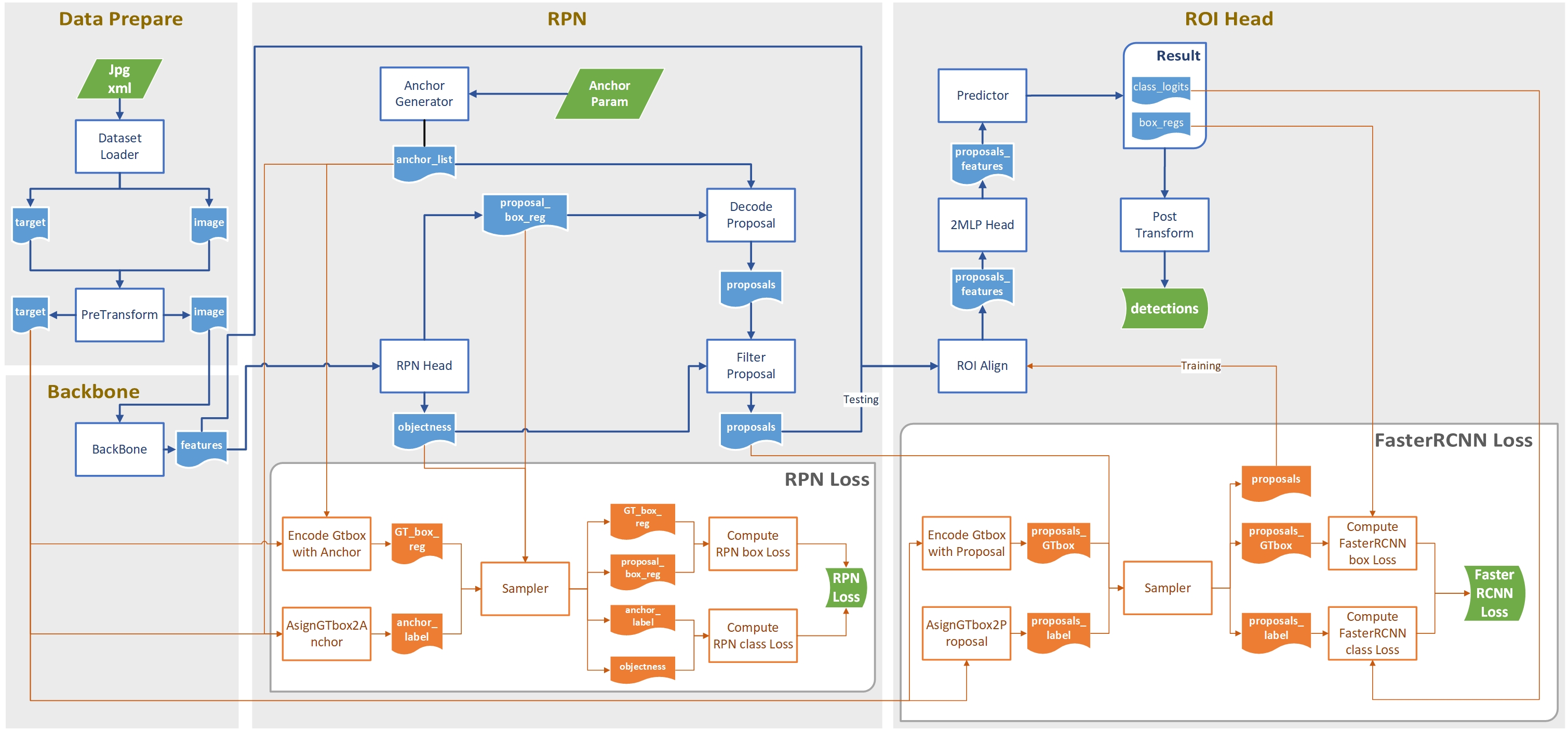
Faster RCNN源码分析(零)—— 整体框架
0. 前言
两段式目标检测的代表作,相当复杂。
基于pytorch的源码,捋一遍Faster-RCNN到底干了啥。
这里先说一下框架,后面有时间再开几篇依次展开说各个子流程的代码实现细节。
1. 从dataset加载图像
首先要从把标注好的图像文件以及标注xml文件读取进来。
参考这里自定义的dataset类,可以知道,dataloader每次迭代返回的是,dataset类__getitem__方法的返回值经过自定义的collate_fn包装过的结果,也就是image tensor的tuple,targets dict的tuple。
而后在送入模型之前,还将tuple转为list,便于cat/stack之类的操作。
另外图像的BN、增广等操作也在这里进行。
本阶段数据转化结果:
image: jpg -> [tensor(3x350x450), tensor(3x375x500)],3x375x450指图像的原始尺寸
target: xml -> [dict1, dict2],dict的结构详见这里
2. 图像预处理
原始图像的尺寸是不保证一致的,因此送入模型的图像都要先进行尺寸缩放、padding等操作。
本阶段数据转化结果:
- image: [tensor(3x350x450), tensor(3x375x500)] -> ImageList,ImageList是一个同时保存预处理之后的图像数据以及padding前缩放后图像尺寸的类。如
1
2{image_sizes = [(800,1028), (800, 1066)]
tensors = tensor(2x3x800x1088)} - target: [dict1, dict2] -> [dict1, dict2],数据类型没有变化,只是其中boxes的坐标进行了同比例缩放
3. Backbone
使用经典分类网络的特征提取部分,作为Backbone,来得到feature map。
以配备了FPN结构的ResNet50为例,Backbone接受上一步的ImageList.tensors之后,将输出5个feature map。这5个feature map被组织为一个dict。
本阶段数据转化结果:
- image: ImageList -> features: dict,dict的结构如下,
1
2
3
4
5
6features = {
0 : tensor(2x256x200x272),
1 : tensor(2x256x100x136),
2 : tensor(2x256x50x68),
3 : tensor(2x256x25x34),
pool : tensor(2x256x13x17)}
4. RPN
RPN可谓是Faster RCNN算法的核心,所有关键内容基本上都杂糅在其中。后续的预测结构,损失也都跟RPN类似。具体来看,依次做了这几件事:
4.1 RPN Head
将所有feature map的value组装为一个list,送入RPN head结构,生成两个量:
- 针对proposal的置信度参数objectness,一个跟输入对应的list
- 针对proposal的边界框回归参数proposal_box_reg,同样是一个跟输入对应的list
本阶段数据转化结果
- features: dict -> objectness: [tensor(2x3x200x272), tensor(2x3x100x136),tensor(2x3x50x68),tensor(2x3x25x34),tensor(2x3x13x17)]
其中[B,C,H,W]中只有C维度的size发生改变,新值3的含义是要在这个feature map上的每一个HW cell上产生3个proposal,tensor的值表示对应proposal的置信度。 - features: dict -> proposal_box_reg: [tensor(2x12x200x272), tensor(2x12x100x136),tensor(2x12x50x68),tensor(2x12x25x34),tensor(2x12x13x17)]
其中C维度12表示每个HW cell上3个proposal的4个边界框回归参数。
4.2 AnchorGenerate
为每一层feature map上的一个HW cell生成一套anchor。
anchor是基于规则生成的,而非输入图像的数据,因此需要指定一套包含几个anchor,每个anchor的面积以及HW比例。生成的这些anchor都用相对于某个中心点的相对坐标表示。
然后定位每feature map的HW cell在原图上的感受野,取感受野左上角元素为中心点,计算得到所有feature map上所有cell的所有anchor在原图上的绝对坐标,用一个list表示。
本阶段数据转化结果
- anchor参数 -> anchor_list : [tensor(217413x4), tensor(217413x4)]
其中,2个tensor对应本batch的2张图像,而且2个tensor的值完全相同,因为anchor是按照规则生成的,只和图像的尺寸有关,与图像的数据无关。另外,$217413 = (200\times272 + 100\times136 + 50\times68 + 25\times34 + 13\times17)\times3$。
4.3 DecodeProposal
用proposal_box_reg和anchor_list进行decode操作,得到proposal,如tensor(2x217413x4)。decode/encode公式如下:
式中,$(A_x, A_y, A_w, A_h)$和$(d_x, d_y, d_w, d_h)$分别为anchor_list和proposal_box_reg的元素,在这里是已知。$(P_x, P_y, P_w, P_h)$为proposal的元素,在这里是未知。
本阶段数据转化结果
- anchor_list: [tensor(217413x4), tensor(217413x4)] + proposal_box_reg: [tensor(2x12x200x272), tensor(2x12x100x136),tensor(2x12x50x68),tensor(2x12x25x34),tensor(2x12x13x17)] -> proposals: tensor(2x217413x4)
4.4 FilterProposal
遍历本batch中的图片,过滤每张图片这数十万个proposal,每张图片只保留2000个/1000个(前者对应训练模式,后者对应预测模式)。筛选的规则如下
- 将每一个feature map得到的proposal视为一个集合,取每个集合中objectness值最大的前2000个/1000个,不足则都算上。
- 将proposal中的越界坐标调整到图像边界上,然后去除H或W小于某个阈值的proposal。
- 去除对应的score小于阈值的proposal,其中score由objectness经sigmoid之后得到。
- 将所有feature map得到proposal视为一个集合,对这个集合做nms,去除与highscore box的iou大于0.7的lowscore box。其中各个feature map之间的proposal不滤除,就是说不会因为f1中的一个highscore box和f2中的一个lowscore box的iou过大,而去除这个lowscore box。
- 在nms之后的结果中,取score最大的前2000个/1000个,作为最终的proposal。
最终得到proposal和score的list。
本阶段数据转化结果
- proposals: tensor(2x217413x4) -> [tensor(2000x4), tensor(2000x4)]
- objectness: [tensor(2x3x200x272), tensor(2x3x100x136),tensor(2x3x50x68),tensor(2x3x25x34),tensor(2x3x13x17)] -> socores: [tensor(2000x4), tensor(2000x4)]
4.5 ComputeLoss
如果是预测模式,那么到上一步RPN模块的工作就结束了。但如果是训练模式,还要继续进行RPN loss的计算。
备注一下,pytorch中计算RPN损失不是基于Filter之后的那2000个proposal,而是在原有的217413个proposal中进行随机抽样256个box,并且尽量保证正负样本的比例为1:1,正样本不够的话就有多少都算上。
我们知道,计算损失的目的是为了量化模型预测结果和真实信息的偏离程度。对于RPN而言,模型输出的预测结果是这些proposal,与之对比的真实信息是图片的GTbox。而对比一个proposal box和一个GTbox,其实是对比他们两个相同属性——坐标&标签,那么量化偏离程度就要从两个角度出发:
以上式中
- 前后两个N在原论文中是不同的值,但是在pytorch源码中,就直接等同为抽样数量了。
- $p_i$指objectness的值,$p_i^*$指proposal的真实标签。
- $\lambda$用来平衡两个损失项,pytorch实现中直接取消了。
- $d_i$指proposal_box_reg的值,$d_i^*$指anchor和与其匹配的GTbox解码出来的边界框回归参数。
- $L_{cls}(p_i,p_i^*)$在原文中是softmax函数,但是因为只有两类,pytorch直接用二值交叉熵进行计算。
4.5.1 边界框坐标损失计算
首先,为anchor_list中的所有anchor分配一个最佳匹配的GTbox(来自图像标注信息target)。匹配的规则是,对于一张图片的一个anchor,计算其与本图片所有GTbox的IOU,与其有最大IOU的那个GTbox,称之为该anchor的最佳匹配GTbox。获得了anchor和GTbox之间的匹配关系后,即可进行预测信息与GT信息之间的对比,从而得到偏离程度,亦即loss。现在有,
因为:
- anchor坐标 + 真实的边界框编码参数 -> GTbox坐标
- anchor坐标 + 预测的边界框编码参数 -> proposal坐标
因此:
- 对比proposal和GTbox坐标的偏离程度等价于对比真实的和预测的边界框编码参数
前者利用anchor和与之匹配的GTbox进行decode得到,后者就是RPN Head输出的proposal_box_reg。这样便得到了边界框坐标损失。
4.5.2 前/后景分类损失计算
前/后景分类损失反映的是一个proposal box的真实标签与预测标签的差异程度。我们已知预测标签就是每一个proposal的objectness值,那么一个proposal的真实标签是什么呢?至少我们的标注信息中是没有直接包含这一信息的。一种合适的做法是,比较匹配的一对GTbox和proposal box之间的IOU。
所谓匹配是指,在4.5.1小节中我们建立了每一个anchor和Gtbox之间的匹配关系,而每一个anchor与RPN head输出的proposal_box_reg结合可以得到一个proposal box,这样这个anchor便将Gtbox和proposal box联系起来了。
具体的做法如下:
- 若它们的IOU极大,说明重合度高,应认为这个proposal是一个前景的提案,其真实标签应为“前景”;
- 若它们的IOU极小,说明重合度低,应认为这个proposal是一个背景的提案,其真实标签应为“背景”;
- 若IOU不大也不小,那么简单地将其视为无效的样本,并且不将其计入损失计算过程。
获得proposal的真实标签(labels)之后,便可将labels和objectness代入交叉熵公式计算损失了。
5. ROI Align
RPN之后,下一步操作所依赖的原理是:经过训练的RPN现在输出的proposal在一定程度上已经足够准确了,可以将一个proposal box认为是一张只包含一个目标的小图片,然后将目标检测的问题转化为图像分类的问题。具体来讲,得到proposal之后,这张小图片从原图上哪个位置截取已经知道了,但是截取下来的内容还不知道,所以要进行本段内容描述的操作。
备注一下,跟RPN计算损失时一样,从这里往后的损失计算也不是所有217413个proposal都使用,而是只在Filter之后的2000个之中随机抽样512个,并且尽可能地保证正负样本比例为1:3。如果是预测模式则不抽样。
另外也不是所有feature map都使用,pooling出来的那一层数据后面也不用。
因此,我们应该将proposal box框住的feature map区域当做下一步处理的对象(而不是原图)。这引入了3个问题:
- RPN得到的proposal box角点坐标都是基于原图的,如何知道一个proposal在feature map上所对应区域的角点坐标呢?
- 在FPN介入的情况下,feature map有多个,如何知道将一个proposal box映射到哪个feature map上呢?
- proposal box有大有小,从原图到不同feature map上的映射比例也不尽相同,怎么封装成一个合适的tensor供后续处理呢?
对于第一个问题,确定原图到feature map之间的比例,然后对proposal box坐标进行等比例缩放即可。
对于第二个问题,原论文基于FPN越低层的输入对应越大尺度对象的原则,设计了一个经验公式。
通过这个经验公式,利用proposal box的HW尺寸即可选择一个合适的feature map进行映射。
其实,原论文中的这个公式是基于Fast RCNN的,也就是不采用RPN时的RCNN。因为采用RPN时,每个proposal都是由feature map经过RPN Head直接生成的,因此天然地知道proposal和feature map的对应关系。而Fast RCNN采用Select Search算法得到proposal,缺失这层关系,所以得用这个经验公式。
但是pytorch实现Faster RCNN还是用了这个经验公式进行proposal与feature map的匹配,而不是用RPN自带的信息。
对于第三个问题,采用ROI Pooling或者说ROI Align算法处理,将所有大小各异的proposal feature box缩放成一致大小的tensor。基本原理是,将每个proposal feature box等分成7x7个区域,然后取每个区域内的最大值,这样无论之前的proposal feature box的HW尺寸如何,最后的输出都是一个7x7的大小。如果7x7处理后直接对子区域坐标取整然后maxpool就是ROI Pooling,用更复杂的插值算法得到最值则是ROI Align,当然后者效果更好。
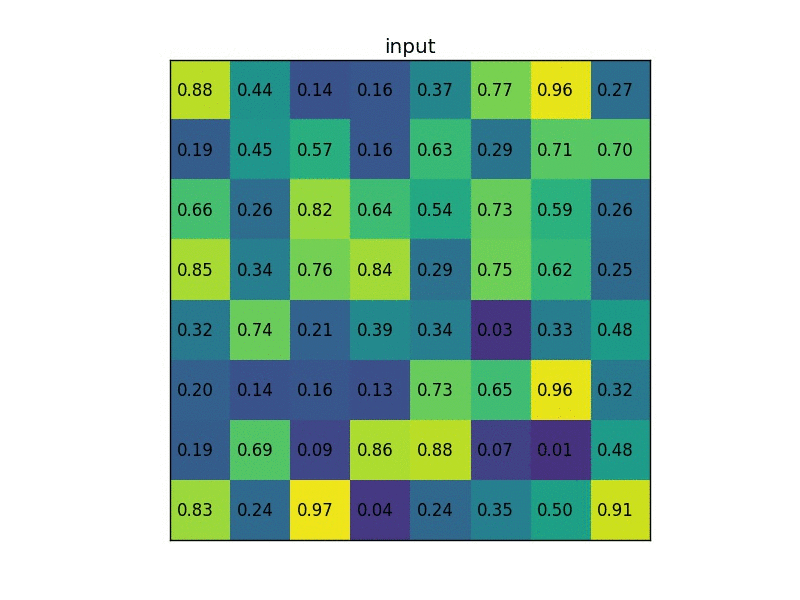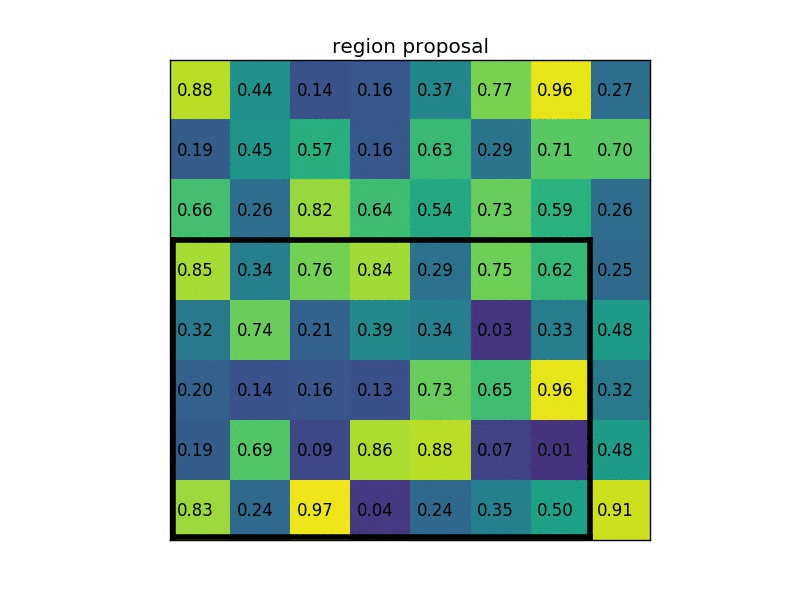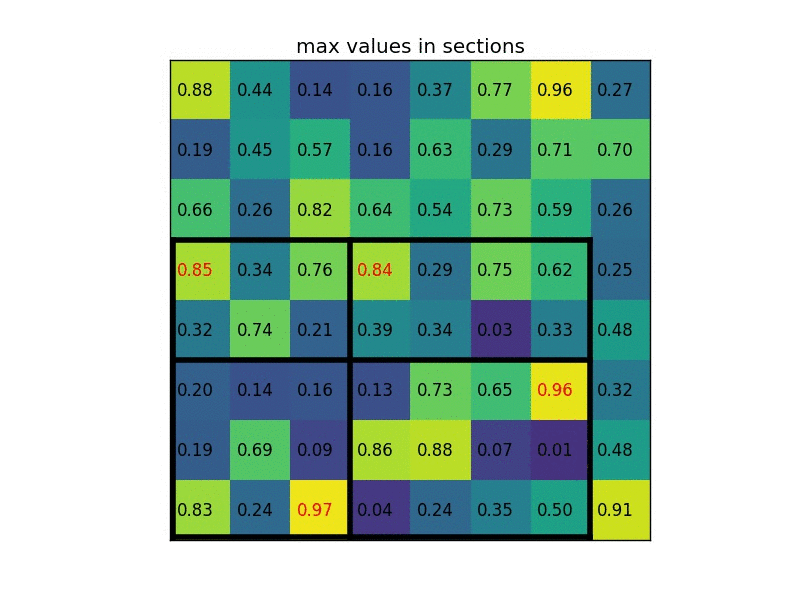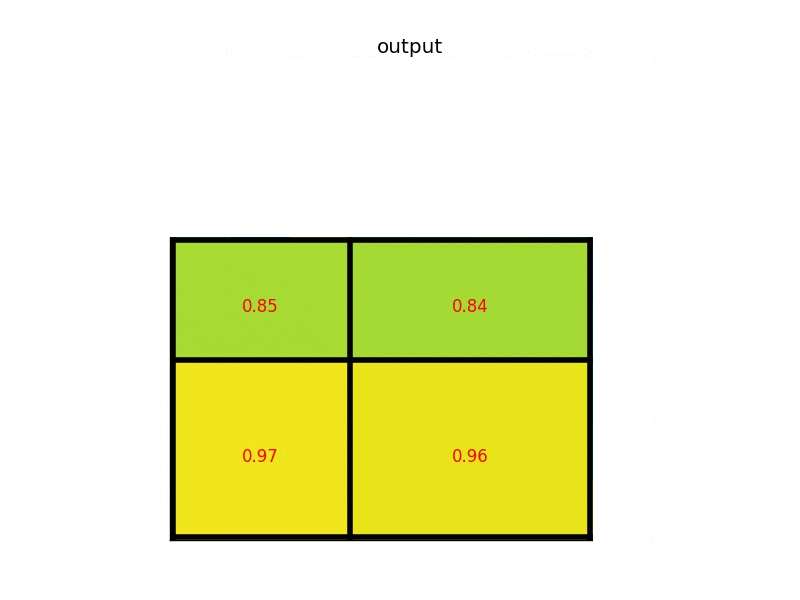
本阶段数据转化结果
- proposal:[tensor(2000x4), tensor(2000x4)] -> proposal:[tensor(512x4), tensor(512x4)] + proposal_Gtbox: [tensor(512x4), tensor(512x4)] + label:[tensor(512x1), tensor(512x1)]
- proposal:[tensor(512x4), tensor(512x4)] + features : dict -> proposal_features: tensor(1024x256x7x7)
如果是预测模式则将以上出现的512替换为1000来理解
6. TwoMLPHead
这一层比较简单,就是将ROI Align之后的proposal_features第一个维度之后的数据flatten,然后通过两个串联的全连接层。
也就是说一个batch处理1024个框,每张图像512个,每个框用一个256x7x7个标量数据组成的列向量表示。如果是预测模式则是每张图像1000个框。
第一层256x7x7个节点,没得选,输入在那,RELU激活;第二层人为设定为1024个节点,同样是RELU激活。
最终得到一个1024x1024的tensor。
本阶段数据转化结果
- proposal_features: tensor(1024x256x7x7) -> tensor(1024x1024)
如果是预测模式,那么应该为1000x256x7x7->1000x1024
7. Predictor
这一层也比较简单,就是将TwoMLPHead输出的tensor通过两个并联的全连接层。这两个全连接层上的结构以及作用与RPN Head基本相同,一个生成类别参数,一个生成边界框回归参数。类别层class_num个节点,边界框层class_num x 4个节点。
这里的预测结果要多说一句,在进入ROI align之前,每张图片的proposal经过过滤剩下512或500个,这个数字对于理解后面的内容、以及以后的内容都非常非常重要。
首先在这里定义,一个proposal产生的一系列最终结果为一组同源detection,那么每张图片会产生512组同源detection。然后,一个proposal框住的feature map数据经过ROI align、MLPHead和Predictor,最终生成21组边界框回归参数和21个置信度。这个21组边界框回归参数都和这一个proposal框进行decode,得到21个final_box。21个置信度经过softmax之后的到21个score。再加上天然存在的序列信息,亦可得到label。
也就是说,一个proposal框住的子图像最终会产生21个detection(一组同源detection)。这意味着一个proposal内哪怕有不同类别的多个目标也还是被同时检测出来。这个结论对于SSD也成立。(YOLOv1你脸红什么?)
这样,每个detection的三个属性label & score & box_reg就都有了。一个detection的结构大致如下图所示(以3个detection,5个类别为例):
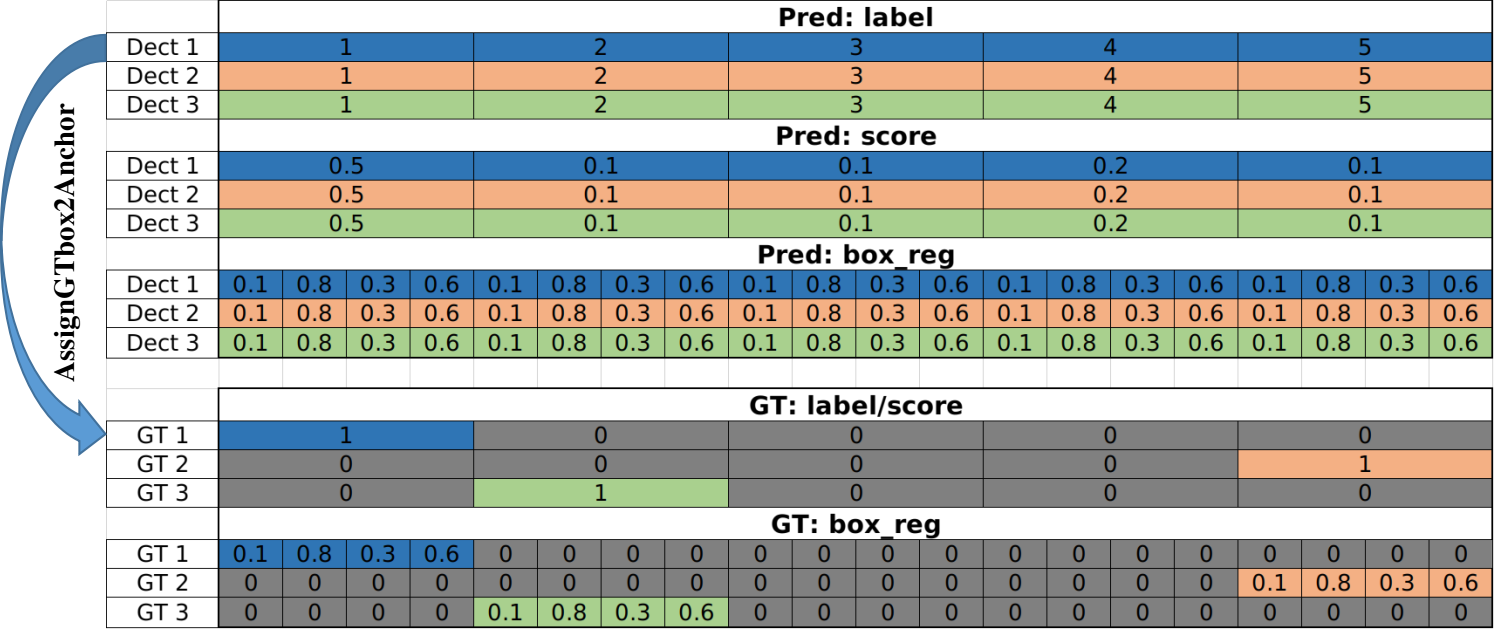
本阶段数据转化结果
- porposal_feature: tensor(1024x1024) -> class_logits: tensor(1024 x class_num) + box_regs: tensor(1024 x [class_num x 4])
数据转化结果中的第一个维度在预测模式下同样应该是1000而不是1024
8A. 预测结果后处理
上一步完成后,实质意义上的模型预测就已经完成了。如果是在预测模式下工作,接下来需要将class_logits和box_regs解释到缩放前的原始图像上。
8A.1 FilterDetection
对于每一张图像,具体工作如下:
- 对class_logits做softmax,得到每一个box的score;
- 对box_reg和proposal角点坐标做decode,得到每一个final_box的角点坐标;
- 类似RPN的FilterProposal,做low score过滤;
- 类似RPN的FilterProposal,做low WH过滤;
- 类似RPN的FilterProposal,针对每一个类别做nms,并且取nms之后的前100个box;
本阶段数据转化结果
- box_regs: tensor(1024 x [class_num x 4]) + proposal: [tensor(512x4), tensor(512x4)] -> final_boxes: [100x4, 100x4],进行decode和filter
- class_logits: tensor(1024 x class_num) -> final_scores: [100x1, 100x1],进行sotfmax和filter
- box_labels: tensor(1024 x class_num) -> final_labels: [100x1, 100x1],进行同步filter
这里的BoxLabel由规则生成,final_labels指的是预测信息,根据上图中box在一个detection的box序列中的相对位置确定。这就跟以往的经验不同了,这里并没有对一个detection所有框的score取最大值,然后将21个类别退化为1,而是将detection的每一列也就是每一个预测框作为一个单独的个体。就是说最终的100个预测框中完全有可能同时存在两个产生自同一个detection。
数据转化结果中的第一个维度在预测模式下同样应该是1000而不是1024
8A.2 PostTransform
将detection三要素中的box坐标根据原图缩放前和缩放后的比例进行等比例缩放即可。
8B. FasterRCNN损失计算
当在训练模式下工作时,需要进行FasterRCNN损失计算。与RPN损失类似,FasterRCNN损失同样分为两部分,坐标损失和分类损失。首先捋一下两部分各自的真实信息和预测信息是什么:
- 坐标回归参数的预测信息,Predictor输出的box_regs;
- 坐标回归参数的真实信息GT_regs,用一对GTbox和proposal进行encode得到;
- 预测框类别的预测信息,Predictor输出的class_logits;
- 预测框类别的真实信息GT_labels,获取方式跟之前RPN类似,即先将proposal和GTbox进行匹配,然后用匹配之后的IOU值的大小来判定proposal是否值得拥有与之匹配的GTbox的label,若值得(IOU>0.5)则proposal的真实label就是GTbox的label,否则为0;
捋清楚了上述信息之后,即可将对应数据代入到类似RPN的损失函数中进行计算,得到FasterRCNN的最终损失。
本阶段数据转化结果
- class_logits: tensor(1024 x classnum) + GT_labels: [tensor(512x1), tensor(512x1)] -> $L_{cls}$
- box_regs: tensor(1024 x [classnum x 4]) + GT_regs: [tensor(512x4),tensor(512x4)] -> $L_{box}$
可以看到真实信息和预测信息之间差了一个classnum的维度,在计算$L_{cls}$时不要紧,因为交叉熵计算用到的GT_label是one-hot的形式,pytorch的实现机制自己会进行合理的计算。
在计算$L_{box}$时,要增加一个classnum上的索引将其退化为1,从而与GT_regs保持一致。索引的来源是GT_label的one-hot向量中1的位置,所以也就是说将GT_reg拓展为four-hot即可。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!