SSD源码分析 —— 整体框架
0. 前言
最近忙着搞超声波,SSD的源码分析拖得有点久了。不过鉴于SSD的模型结构比较简单,而且较为复杂的gtbox匹配、损失计算等机制在Faster RCNN业已理解,所以前后也没用多长时间。
首先,还是算法的总体流程图,可以看出比Faster RCNN那是简单太多了。
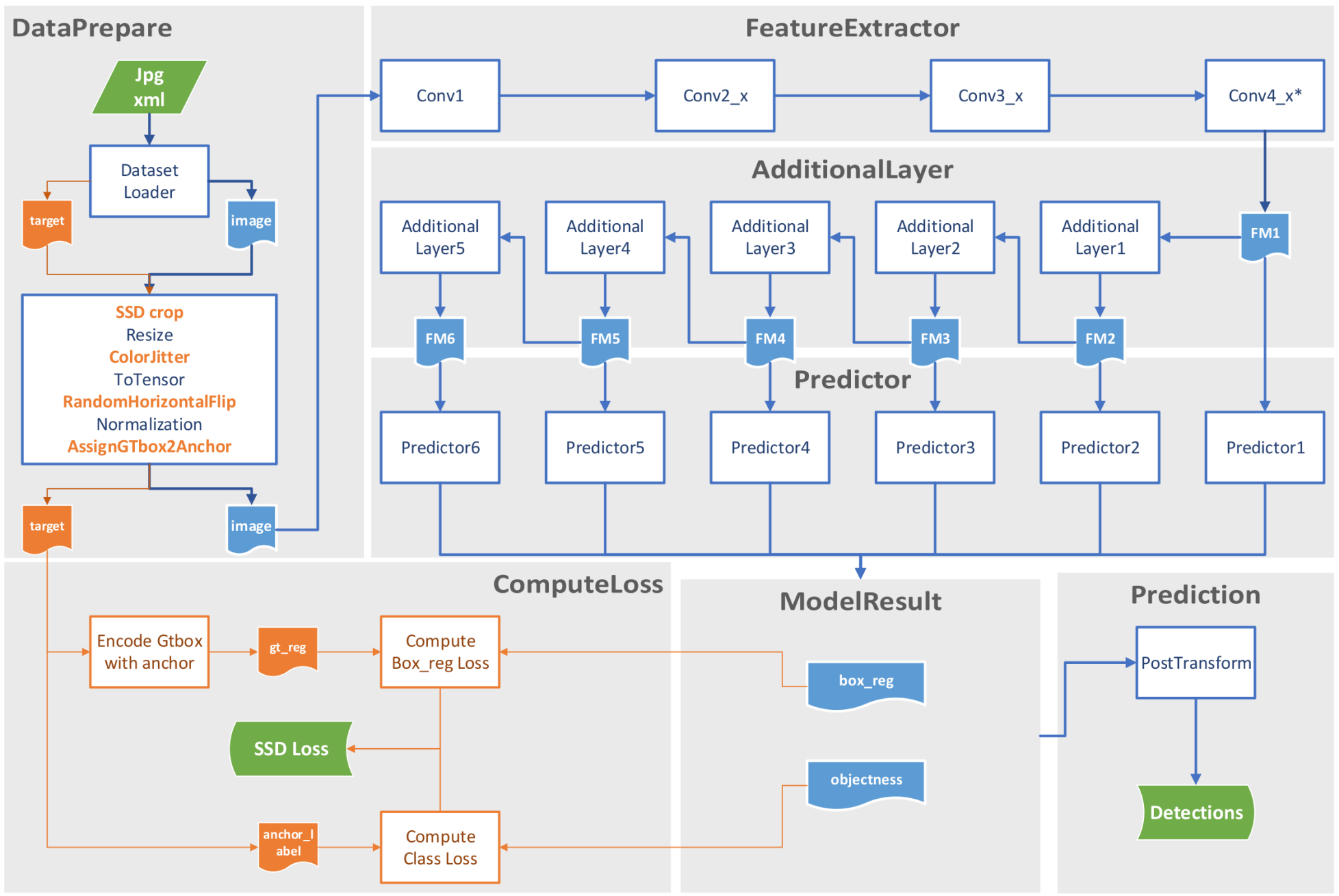
第一步还是从dataset中加载图像,然后经过图像预处理,再通过以ResNet50为蓝本的feature extractor处理,结果再送到5个additional layer中,最终连同feature extractor的输出合计得到6个feature map,每个feature map再各自通过一个predictor进而得到预测结果(box_reg和objectness)。
其中box_reg为相对于anchor的边界框回归参数,objectness经过softmax之后就是对应类别的置信度。如果是训练模式,就用这两个信息去求模型损失;如果是预测模式则对所有的边界框进行筛选得到最终的预测结果。
其中anchor还是老样子,从6个feature map每一个的HW cell上面长出来2-3个,不同feature map上anchor的scale和ratio都不同,以达到金字塔的效果。
1. 从dataset加载图像
首先要从把标注好的图像文件以及标注xml文件读取进来,经过一系列图像预处理操作转化为tensor格式,大致流程跟之前Faster RCNN差不多。
但是,FasterRCNN的图像预处理有两次:
- 第一次是在创建dataset类实例的时候,就是说从dataset类
__getitem__方法返回的图像数据先经过了一次transform。这一次主要是to_tensor和随机水平翻转(预测模式无)。 - 然后在送入模型之前又通过单独的GeneralizedRCNNTransform类,再transform一次。这一次的细节看这里
回到SSD,预处理只有一次,全部集中在dataset类中实现,而且花样比较多(加*项为训练模式独有):
1.1 SSDcrop*
顾名思义,这是SSD的特点之一。目的是为了在一张原始图片上截取一个子区域作为模型的输入,而不是整图送进去。而且很明显,不是在原图上随便截就可以,截出来的子区域要符合一定条件:
- HW比例不能太夸张,要在1:2以内;
- 跟所有GTbox的IOU都要在一个合理范围内,这个合理范围在[0.1, inf], [0.3, inf], [0.5, inf], [0.7, inf], [0.9, inf], [-inf, inf]中随机选取。
- 至少有一个GTbox的中心点在这个子区域内。
得到一个满足全部3个条件的子区域后,进行下一步。这意味着,对于一个epoch,这张图片只有一个子区域得到了有效使用,而且下一个epoch对于这张图片很有可能又换了一个子区域。
相同,又不完全相同;重复,又不完全重复。艺术啊!
本阶段数据转化结果:
- image: jpg(375x500) -> jpg(252x438)
这一步的目的目测是为了扩充训练集的样本数量,但是这样不保持原图比例的裁剪然后再缩放,相比于预测时只是缩放不裁剪,真的可以吗?而且预测时这种不考虑原图HW大小和比例,直接硬缩放为300x300,直觉上也感觉不太对。mark
1.2 Resize
简单粗暴调用官方库torchvision.transforms.Resize(),利用双线性插值原理将裁剪后的图像/原始图像,缩放到300x300。
本阶段数据转化结果:
- image: jpg(252x438) -> jpg(300x300)
SSD使用了一个简单而高效的机制来处理图像缩放过程中的GTbox坐标变化,就是将GTbox的坐标以图像比例坐标的方式存储,这样不管图像缩放多少,用这个比例坐标乘以新的尺寸即可得到正确的GTbox坐标。
1.3 ColorJitter*
调用官方库torchvision.transforms.ColorJitter(),在HSV空间将图像数据随机抖动一下。
本阶段数据转化结果:略
1.4 ToTensor
PIL image格式转成tensor,换言之,之前的操作都是以PIL image格式进行的。
本阶段数据转化结果:
- image: jpg(300x300) -> tensor(3x300x300)
1.5 RandomHorizontalFlip*
随机水平翻转,不解释了。
本阶段数据转化结果:略
1.6 Normalization
数据归一化,三通道的均值和方差还是取自ImageNet,mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225]。
本阶段数据转化结果:略
1.7 AssignGTbox2Anchor*
又来了,Anchor与GTbox匹配的概念并不新奇,但这个实现方式却是SSD的鲜明特点。
为什么?因为在SSD的One-Stage理念下,不存在proposal概念,或者说anchor就是最终的proposal,而这个proposal又是预先按照既定参数生成的,不是来源于图像数据本身的。也就是说,对于SSD而言从一开始就知道proposal框的坐标,因此在预处理的时候就把Anchor与GTbox的匹配给做了。
这一步实际产生的效果是,按照anchor的排列顺序产生与之匹配的GTbox的序列以及label的序列,用以替换target中来自xml文件中的box和label信息。这样在后面计算损失时用到GT信息时,可以直接decode target中的box得到GT_box_reg,然后直接与预测的box_reg进行smooth L1损失计算。
本阶段数据转化结果:
image: 无变化
GTbox: tensor(1x4) -> tensor(8732x4)
2. FeatureExtractor
其实还是一个Backbone的概念,目的是为了从原始图像中提取出Feature map。这里还是以ResNet50为例,取其第一个卷积层conv1以及后续的3组Residual结构作为Backbone。
其中值得注意的是,第3组Residual结构conv4_x不是照搬过来的,而是将其这一组的6个Residual结构中的第一个的步距由2调整为1。原理这一个Residual结构因为身处组内第一的位置,因此要承担调整HW尺寸不断折半的任务,但是这里调整了stride,不用折半了。
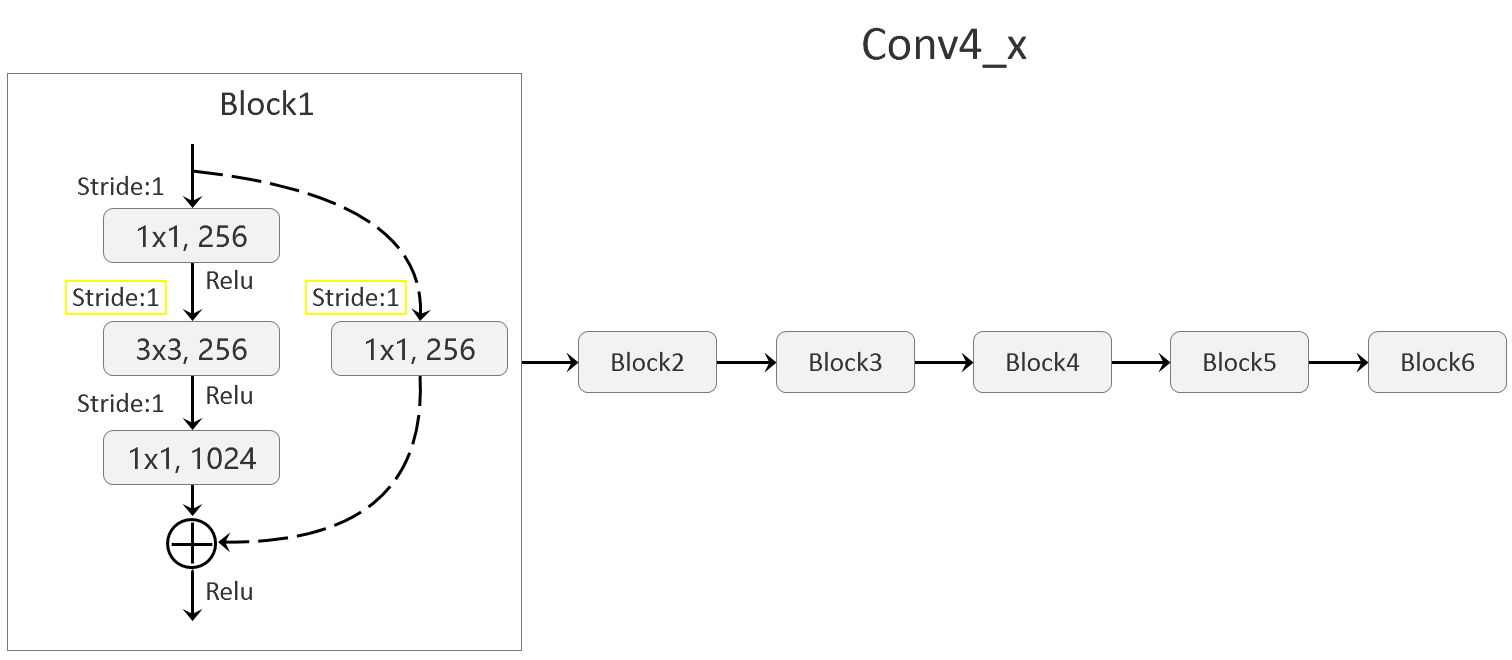
本阶段数据转化结果:
- image: tensor(3x300x300) -> tensor(64x150x150) -> tensor(256x75x75) -> tensor(512x38x38) -> tensor(1024x38x38)
如果不调整conv4_x,那么最后一个tensor应该是1024x38x38x19
3. AdditionalLayer
为了在不同尺度上得到更加准确的预测结果,这里又额外构造了5个AdditionalLayer结构,在Backbone输出的基础上继续进行卷积运算。
每一个AdditionalLayer结构都是由两个串联的ConvBNRelu单元组成,不断的缩小feature map的HW尺寸,以使得越往后的HW cell对应更大的原图感受野。
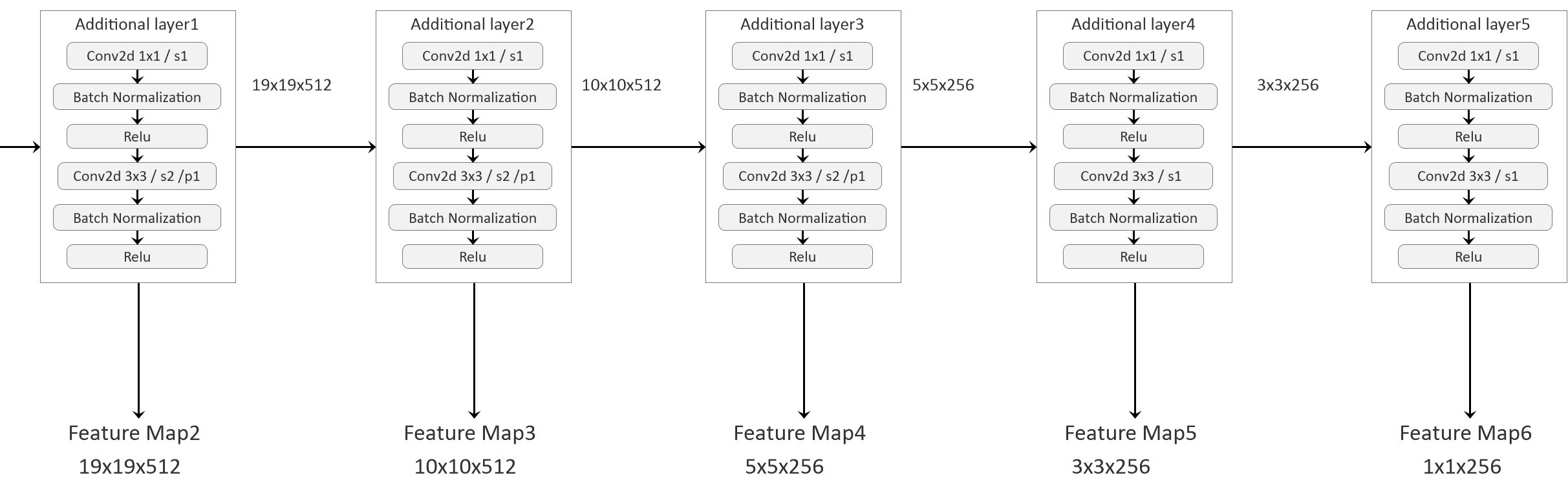
本阶段数据转化结果: 详见上图
4. AnchorGenerator
未在总流程图体现的一点是AnchorGenerator,因为anchor是基于规则生成的。老样子,还是为每一个feature map上的每一个HW cell生成一套anchor,并且总体上还是遵循在不同的feature map上生成不同scale的anchor。但是相比于用了FPN的Faster RCNN,SSD的AnchorGenerator的规则有一些自己的特点。
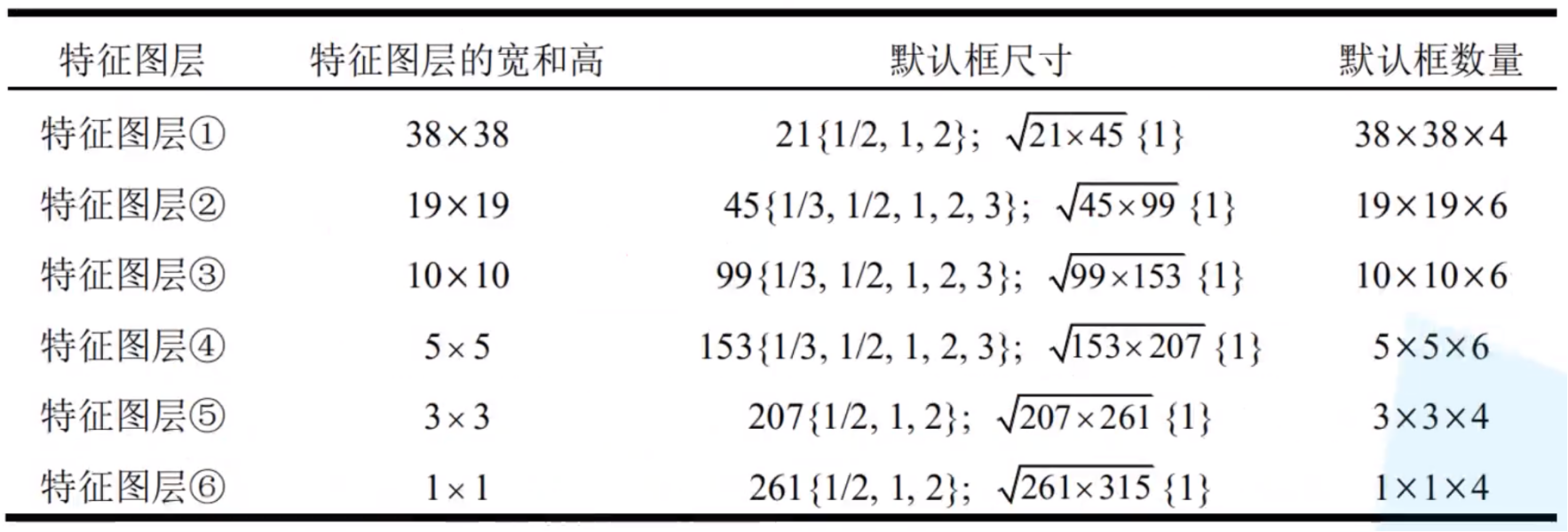
按照上表的规则生成的这些anchor都直接用在300x300图像上的比例坐标表示,而不是向FasterRCNN一样,用相对于某个中心点的相对坐标。
本阶段数据转化结果
- anchor参数 -> anchor : tensor(8732x4)
5. Predictor
得到6个feature map之后,将其分别送入一个Predictor。每个Predictor包含两个卷积结构,一个用来生成objectness,一个用来生成box_reg。具体的结构也比较简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# box_extractor
ModuleList(
(0): Conv2d(1024, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
# objectness_extractor
ModuleList(
(0): Conv2d(1024, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
可以看到,3x3的卷积,SAME PADDING,1 STRIDE,就是不改变卷积前后的HW尺寸,只调整深度:
- 对于box_extractor,深度调整为4 x anchor_num;
- 对于objectness_extractor,深度调整为21 x anchor_num。
例如,1024x38x38的feature map在经过box_extractor处理之后,得到一个16x38x38的tensor。16的来由是这一层feature map上的每个cell生成4个anchor,而每个anchor有4个坐标值。就是说,1个HW cell的每4个通道组成一组完整的box_reg参数。然后再将这个16x38x38的tensor reshape成5776x4,即可得到第一个feature map生成的5776组box_reg参数,同理可以得到其余的box_reg参数,最后拼成一个8732x4的box_reg。
类似地,1024x38x38的feature map在经过objectness_extractor处理之后,得到一个84x38x38的tensor,将其reshape为5774x21然后再去拼接,最终得到8732x21的objectness。
这里出现了取消proposal的另外一个优势,因为没有了proposal,所以300x300的图像上所有数据或者说一个feature map上的所有数据,都会被拿来使用,所以不存在需要使用ROIalign的场景。
然后,来回忆一下FasterRCNN中的detection概念。由于未做过滤和采样,因此8732个anchor全部参与后续计算,这意味这最终将产生8732个detection。而且因为box_extractor的结构跟FasterRCNN不同,SSD每个detection的结构跟FasterRCNN也略有不同,SSD的一个detection只有1组box_reg参数,而FasterRCNN是21组,也就是每个类一组。
FasterRCNN的detection结构如下:
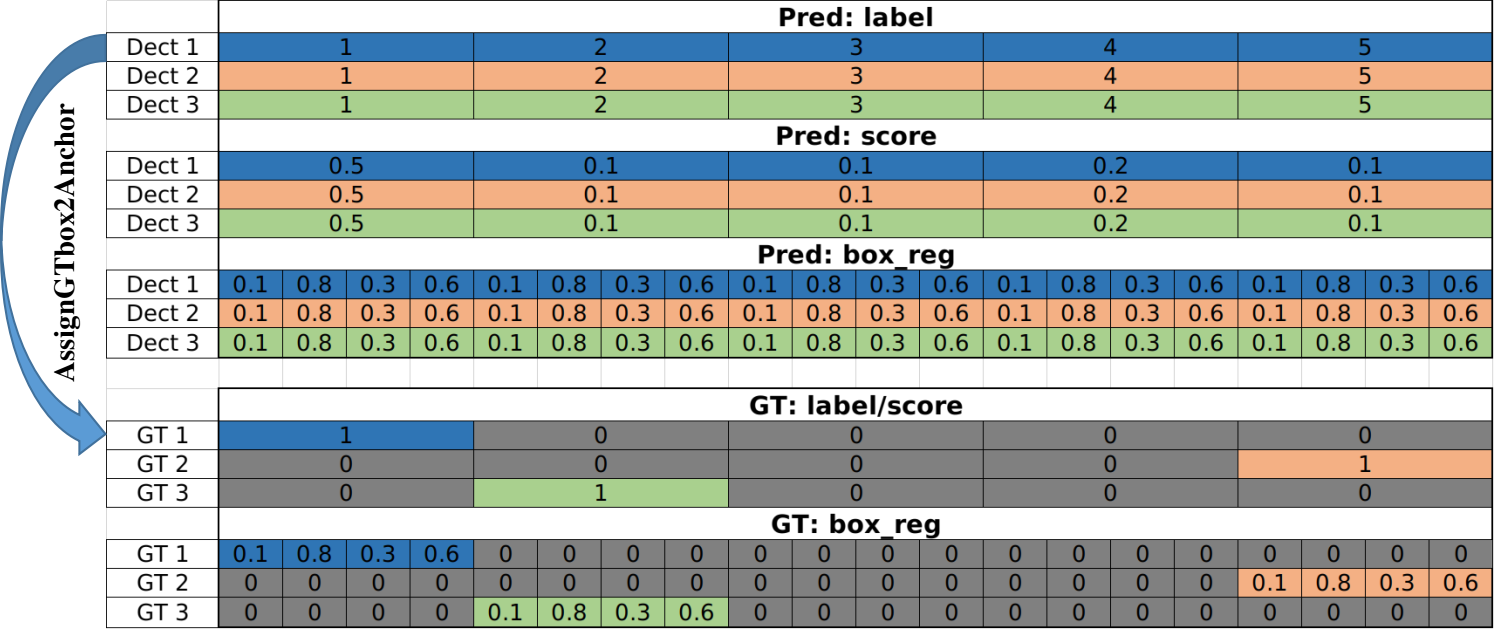
SSD的detection结构如下:
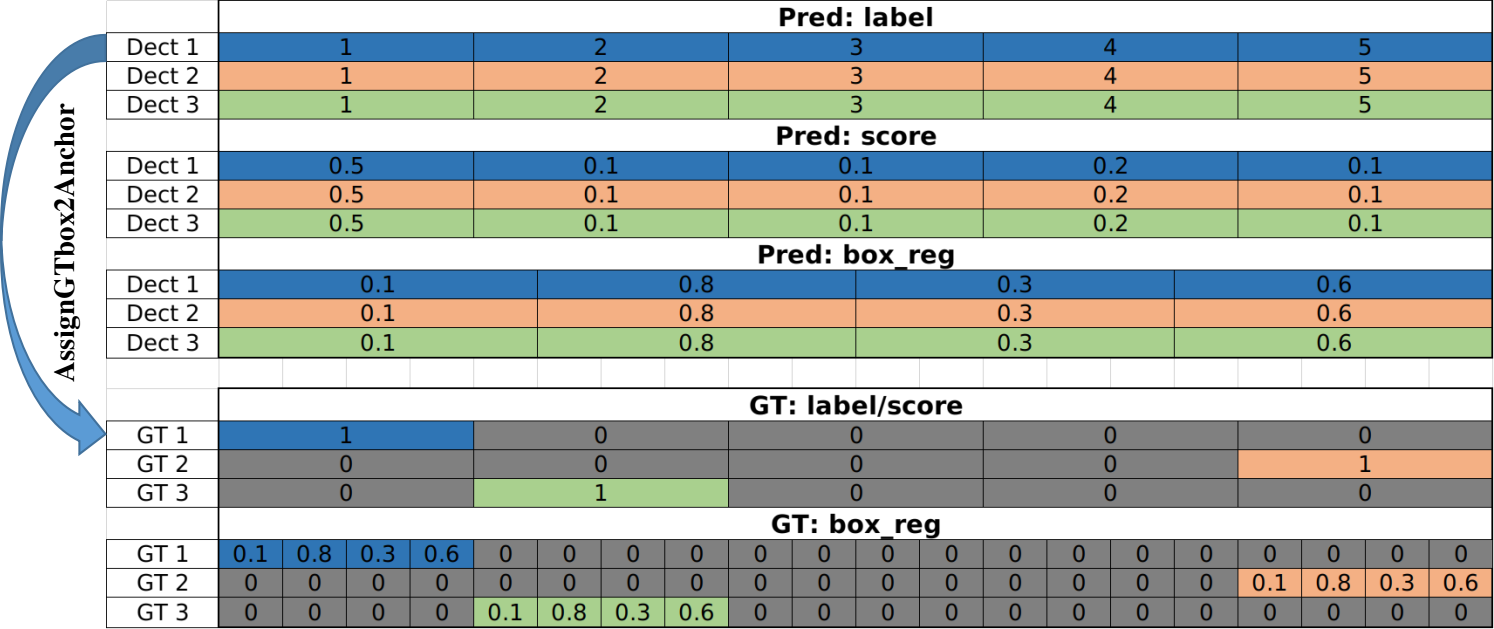
本阶段数据转化结果
- feature map1: tensor(1024x38x38) -> objectness1: tensor(84x38x38) + box_reg1: tensor(16x38x38) -> objectness1: tensor(5776x21) +box_reg1: tensor(5776x4)
- objectness1 + … + objectness6 -> objectness: tensor(8732x21)
- box_reg1 + … + box_reg6 -> box_reg: tensor(8732x4)
6A. 预测结果后处理
上一步完成后,实质意义上的模型预测就已经完成了。如果是在预测模式下工作,接下来需要将objectness和box_reg解释到缩放前的原始图像上。
6A.1 FilterDetection
对于每一张图像,具体工作如下:
- 对class_logits做softmax,得到每一个box的score;
- 对box_reg和anchor角点坐标做decode,得到每一个final_box的角点坐标;
- low score过滤;
- low WH过滤;
- 针对每一个类别做nms,并且取nms之后的前100个box;
本阶段数据转化结果
- box_reg: tensor(8732x4) + anchor: tensor(8732x4) -> final_boxes: tensor(100x4)
- objectness: tensor(8732x21) -> final_scores: tensor(100x1)
- box_label: tensor(8732x21) -> final_labels: tensor(100x1)
和FasterRCNN相同,这里的BoxLabel由规则生成,final_labels指的是预测信息,根据上图中box在一个detection的box序列中的相对位置确定。这就跟以往的经验不同了,这里并没有对一个detection所有框的score取最大值,然后将21个类别退化为1,而是将detection的每一列也就是每一个预测框作为一个单独的个体。就是说最终的100个预测框中完全有可能同时存在两个产生自同一个detection。
6A.2 PostTransform
将detection三要素中的box坐标根据原图缩放前和缩放后的比例进行等比例缩放即可。
6B. SSD损失计算
当在训练模式下工作时,需要进行SSD损失计算。与FasterRCNN损失类似,SSD损失同样分为两部分,坐标损失和分类损失。首先捋一下两部分各自的真实信息和预测信息是什么:
- 坐标回归参数的预测信息,Predictor输出的box_reg;
- 坐标回归参数的真实信息GT_regs,用anchor和与之匹配的GTbox进行encode得到;
- 预测框类别的预测信息,Predictor输出的objectness;
- 预测框类别的真实信息GT_labels,先将anchor和GTbox进行匹配,然后用匹配之后的IOU值的大小来判定proposal是否值得拥有与之匹配的GTbox的label,若值得(IOU>0.5)则anchor的真实label就是GTbox的label,否则为0;
捋清楚了上述信息之后,即可将对应数据代入到FasterRCNN的损失函数中进行计算,得到SSD的最终损失。
另外,具体还有一些细节需要注意:
- 定位损失和分类损失SSD取1:1。
- 定位损失只统计真实标签不为0的anchor,或者说基于这个anchor产生的GT_reg和box_reg,即所谓正样本。
- 分类损失统计全部的正样本,然后再选取3倍的负样本。并且负样本不是像FasterRCNN那样随机选取,而是选取负样本中损失最大的那些。例如这一个batch有10个正样本,那么就应该选取交叉熵损失最大的30个负样本。而且负样本的数量不应超过8732。据原论文称可以这样做可以加速收敛。
本阶段数据转化结果
- box_label: tensor(8732x21) + GT_labels: tensor(8732x21) -> $L_{cls}$
- box_reg: tensor(8732x4) + GT_regs: tensor(8732x4) -> $L_{box}$
同样跟FasterRCNN一样,可以看到真实信息和预测信息之间差了一个classnum的维度,在计算$L_{cls}$时不要紧,因为交叉熵计算用到的GT_label是one-hot的形式,pytorch的实现机制自己会进行合理的计算。
在计算$L_{box}$时,要增加一个classnum上的索引将其退化为1,从而与GT_regs保持一致。索引的来源是GT_label的one-hot向量中1的位置,所以也就是说将GT_reg拓展为four-hot即可。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!