YOLO源码分析(零) —— 理论基础
0. 前言
One-Stage目标检测的另一代表,特点是GridCell的切分以及与之配套的GT框和anchor的匹配机制。
现在看下来YOLO的故事是,YOLOv1先定下基础,然后后面的版本用各种各样的trick改善v1的效果。因此,要首先搞清楚v1都干了些啥,然后再依次搞清楚后续各个补丁的含义。
而且由于YOLOv1的检测效果相对而言并不是很好,目前应用的至少是v3起步,所以对于v1和v2只在理论层面分析一下,源码的分析直接从v3开始。
1. YOLOv1解析
1.1 模型结构
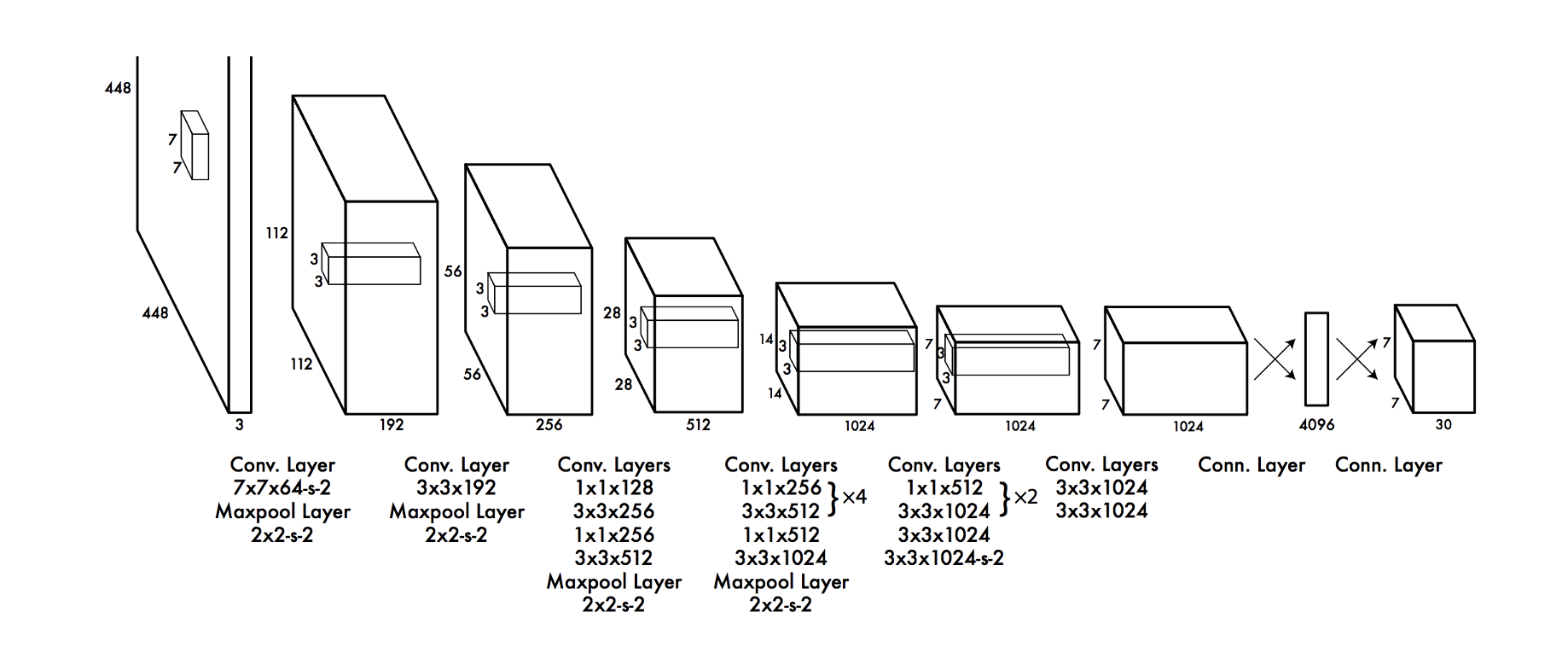
看上面这个模型结构图可知,第一代YOLO的特点就是“简单+粗暴”,从image输入到detection输出,全过程看起来就跟一个分类网络模型没有任何区别。只不过是将分类网络最终输出的21维列向量(以PascalVOC)扩充为下面这个30维列向量(以7x7切分cell,每个cell 2个final_box为例):

这样的模型输出向量有7x7个,也就是模型结构图中最后的那个30x7x7的tensor,刚好对应原图7x7个cell。对其中的一个按深度方向的行向量而言,有
- 20位作为每个类别的score
- $(4+1)\times2 =10$位作为两个框的信息,4对应角点坐标,1对应YOLO独有的“框的置信度”,后面会详细展开。
1.2 损失函数
个人感觉YOLOv1的一切秘密其实都藏在它的损失函数中,先看公式:
非老手的话一眼看过去是有点懵逼的,不过一项一项捋一下也不算难。
首先以L1为例,可以看出这一项是用来计算预测框的中心点坐标与GT框中心点坐标之间的偏离程度,不带帽的量是GT,戴帽的是预测。式中的均方根误差,不难理解。$\lambda{coord}$是权重系数,也不难理解。唯一的难点在于如何理解$\sum{i=0}^{S^2}\sum{j=0}^{B} 1{ij}^{obj}$?
第一个问题:从累加符号的上标可以看出i是在遍历这7x7个GridCell,j是在遍历一个GridCell中的B个预测框,这样用i和j去遍历所有预测框是一个很直观的事情。但是,如何确定一个预测值对应的GT值是哪个呢(换句话说,$x_i$是谁)?这是从图像分类任务进阶到目标检测任务所要面对的核心问题,FasterRCNN和SSD用的都是AssignGTbox2Anchor机制,而YOLO的答案不一样,其特点也正在于此。
YOLO的具体做法是,当遍历到第$i$个GridCell的第$j$个预测框时,一一查看所有的GT框,将中心坐标在当前GridCell中的挑选出来。此时有三种情况:
- 所有GT框的中心点都不在当前GridCell内,那么pass,接着计算第$i+1$个GridCell。
- 刚好有1个GT框的中心点在当前GridCell内,那么这个GT框的参数就是我们在找的$x_i, y_i, w_i, h_i$。
- 有不止一个GT框的中心点在当前GridCell内,那么随机选取一个GT框。
综上,对于L1而言,每一个GridCell最多只有一个GT值有效,这也是为什么$x_i$的下标只有i。那为什么预测量的下标也只有$i$没有$j$呢?因为对于一个GridCell,跟GT框一样,预测框也只选取一个去计算损失。但不是随机选取,而是选取这个B个预测框中$\hat{C}$值最大的那个。
L2同理,唯一不同的是多了根号。这是考虑IOU相等的两对GT框和预测框,一对尺寸很大,一对尺寸很小,那么此时因为IOU相同,应该认为两对的匹配程度是一样好的。但是,去计算L2损失时显然尺寸大的这一对预测框和GT框之间宽度和高度的差值更大,这是不合理的。因此YOLO的作者加了个根号用来缓解这一问题。
然后L3也类似,不过要说明下“框的置信度”的真值$C_i$从何而来。它是对于这一个GridCell被选中的一对GT框和预测框的IOU值。
L4跟L3完全一样,只不过计入损失的GridCell的选取规则刚好反过来,这里是没有目标才计入损失。
L5有点不一样,这里计算的是类别损失,所以不再遍历B个预测框。真实值$p_i$是一个one-hot向量,预测值$\hat{p}_i$就是那个20位的score向量。
个人感觉何必那么麻烦,直接先说好,对于一个30维的预测结果,只有confidence最大的那个框有效,其他框权当做没有不就完了。
1.3 一点体会
这三种主流目标检测模型基本流程其实都可以总结为:
在输入图像上选取一个区域,将这个区域的图像数据扔到一个CNN网络中加工出来一个detection结构,然后将这个detection结构解释为预测框的信息。
对于第一点,选取子图:
- FasterRCNN比较讲究,专门搞一个RPN模型去确定应该截取哪些区域,可以说是“一图一策”;
- YOLOv1粗暴一点,直接将原图切成7x7份,然后将每一个子图扔到CNN中加工,然后借用滑动窗口的卷积实现原理直接将整张图扔进去,同时得到49个子图产生的detection结构。
- SSD和YOLOv1一样,在原图上划分8732个子区域,然后利用滑动窗口的卷积实现原理得到8732个子图产生的detection结构。
然后关键来了,那就是三种算法中一份子图产生的detection结构是怎样的?
- YOLOv1的上面已经画出来了,是一个30维的向量,是最简单的一个,但这也意味着这部分子图上的原始数据最终只产生了一个预测框。mark,YOLO针对一个detection结构生成20个还是1个框有待确认
- SSD的在之前也画出来过,是1个4维的box_reg向量和1个21维的objectness向量。这意味着原图上一个anchor圈住的原始数据最终产生了1个框,然后这个框可以被21个类别复用,所以还是相当于21个框。另外,SSD的这么多anchor之间有很严重的范围相互覆盖,这意味着对于300x300原图上的某一个小区域来讲,其实是被重复利用了很多次。而YOLO各个子图之间是没有交集的,所以原始数据利用率就差一些。
- FasterRCNN的最复杂,是1个84维的box_reg向量和1个21维的objectness向量,也就是产生21个位置不同的框。也就是说用一个proposal内的原始数据产生了21个预测框,数据利用率相对而言是最高的。
2. YOLOv2解析
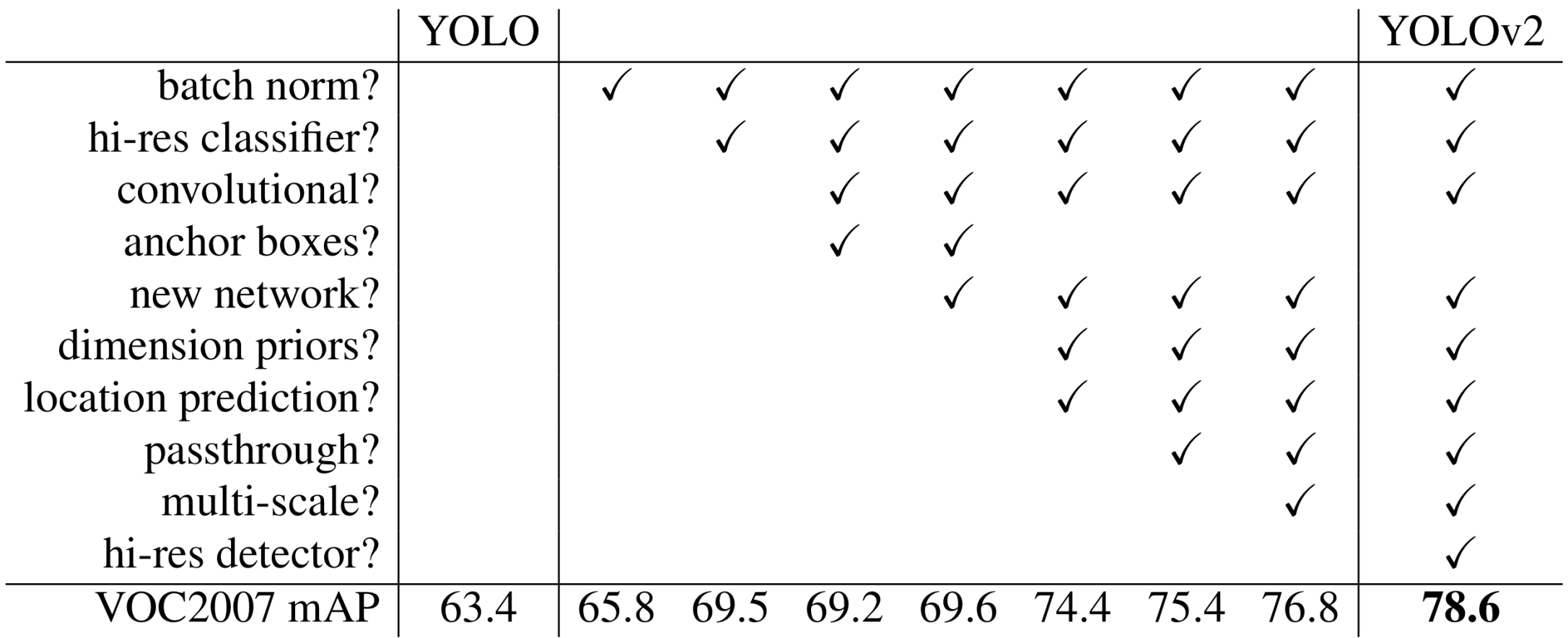
YOLOv2是在v1的基础上打补丁,一个一个地理解下这些补丁即可。
2.1 模型结构升级
最显著的升级当然是模型的结构,包括更换backbone,增加BN层,多尺度融合等。
首先,v2的backbone由v1中一个GoogleNet的简化版,改变为Darknet系列,这里以Darknet19为例。
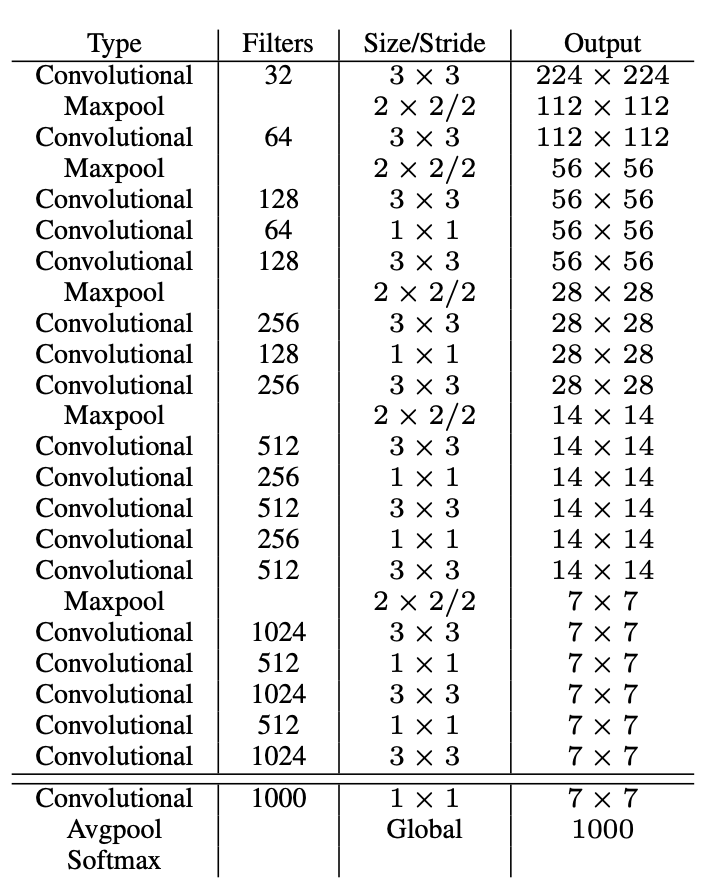
上图为Darknet19作为分类网络时的完整结构。作为目标检测网络则去掉上图最下方分界线下面的部分,然后增加亿点点细节,得到:
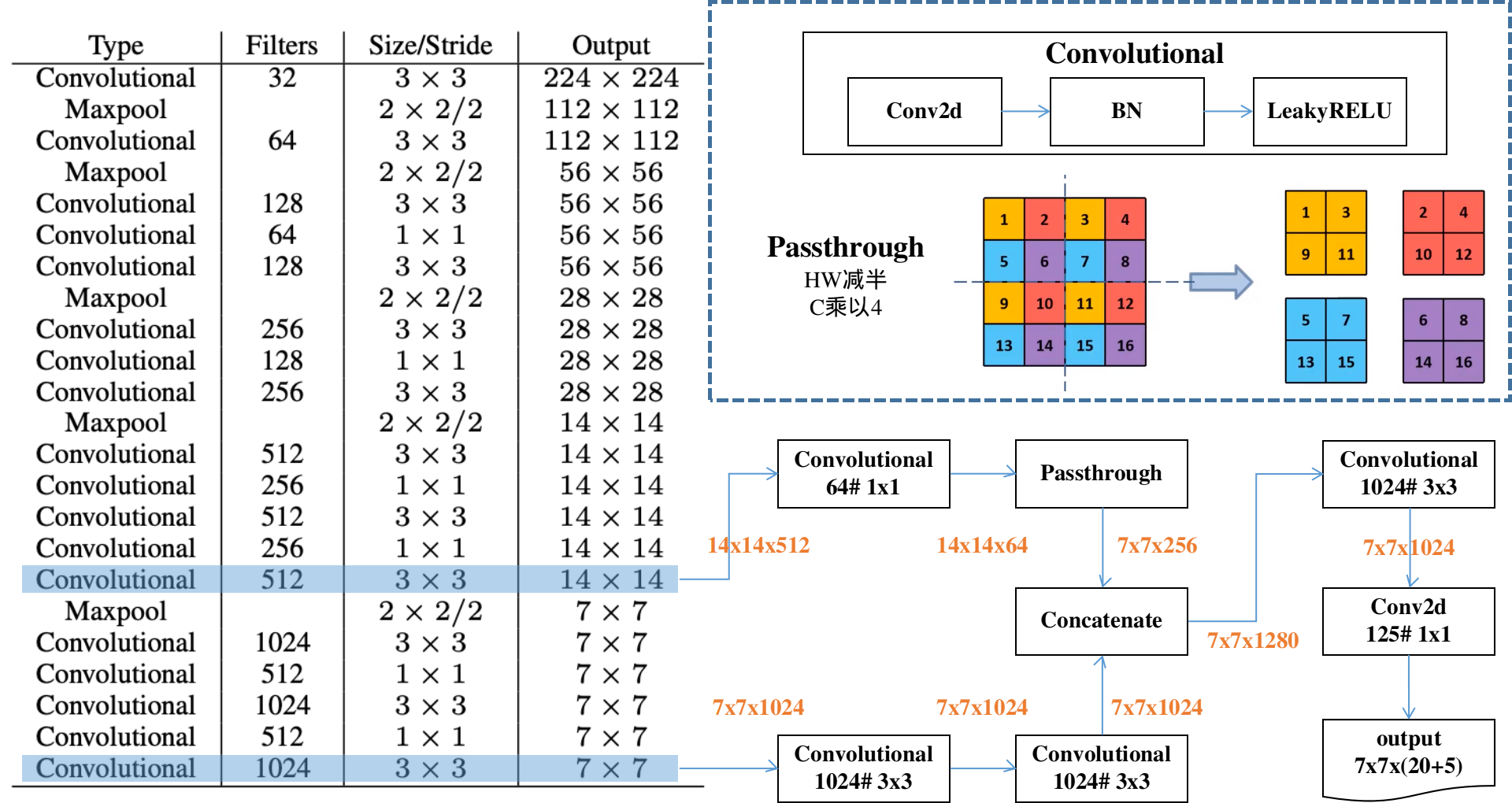
2.2 增加anchor
鉴于v1表现不佳的现象主要集中于定位误差,因此v2也不得不采用了anchor概念。而且其对于anchor的用法也有一些特色,需要注意有:
- 每个GridCell分配5个不同尺寸和比例的anchor,中心点都设定在GridCell左上角,就是说现在的一个GridCell的原始数据现在可以产生5个结果向量。
- 5个anchor的尺寸和比例通过K-means方法对训练集中的GT框尺寸进行聚类得到。
- 结果向量中的xywh现在自然也成了参数,需要联合anchor坐标进行decode才能得到预测框的位置。而且其decode公式也有点意思,具体如下:其中,$b$为最终检测框的位置参数,$\hat{C}$为检测框的置信度,$t$为结果向量中的元素,$A$为anchor的位置参数。$\sigma$为sigmoid函数,用来将预测框的最终位置限制在自己的GridCell内。
2.3 其他改进项
- 训练分类器网络时采用448x448的高分辨率数据,以往都是采用224x224;
- 训练目标检测网络时,每10个batch就在{320, 352, … , 608}的范围内随机选取一个尺寸对原始数据进行缩放,然后输入到网络中;
3. YOLOv3解析
YOLOv3继续打补丁,不过这次不仅更换了网络结构,连损失函数也变了。另外,预测框与GT框的匹配办法也升级了,不过这个工作应该在v2就已经做了,只不过v2的原论文没有提及,真要想搞清楚v2预测框与GT框的匹配方式,还是要阅读v2的源码,不过感觉没必要。
所以v3的升级也分为模型升级,匹配方式,损失函数等3个方面来说明:
3.1 模型结构升级
backone引入了ResNet中的残差结构,形成Darknet53,具体结构如下表所示,

然后增加FPN等亿点点细节,得到目标检测网络:
output3对应32x32的GridCell切分方式,用于检测小目标;output1对应8x8的切分方式,用于检测大目标。
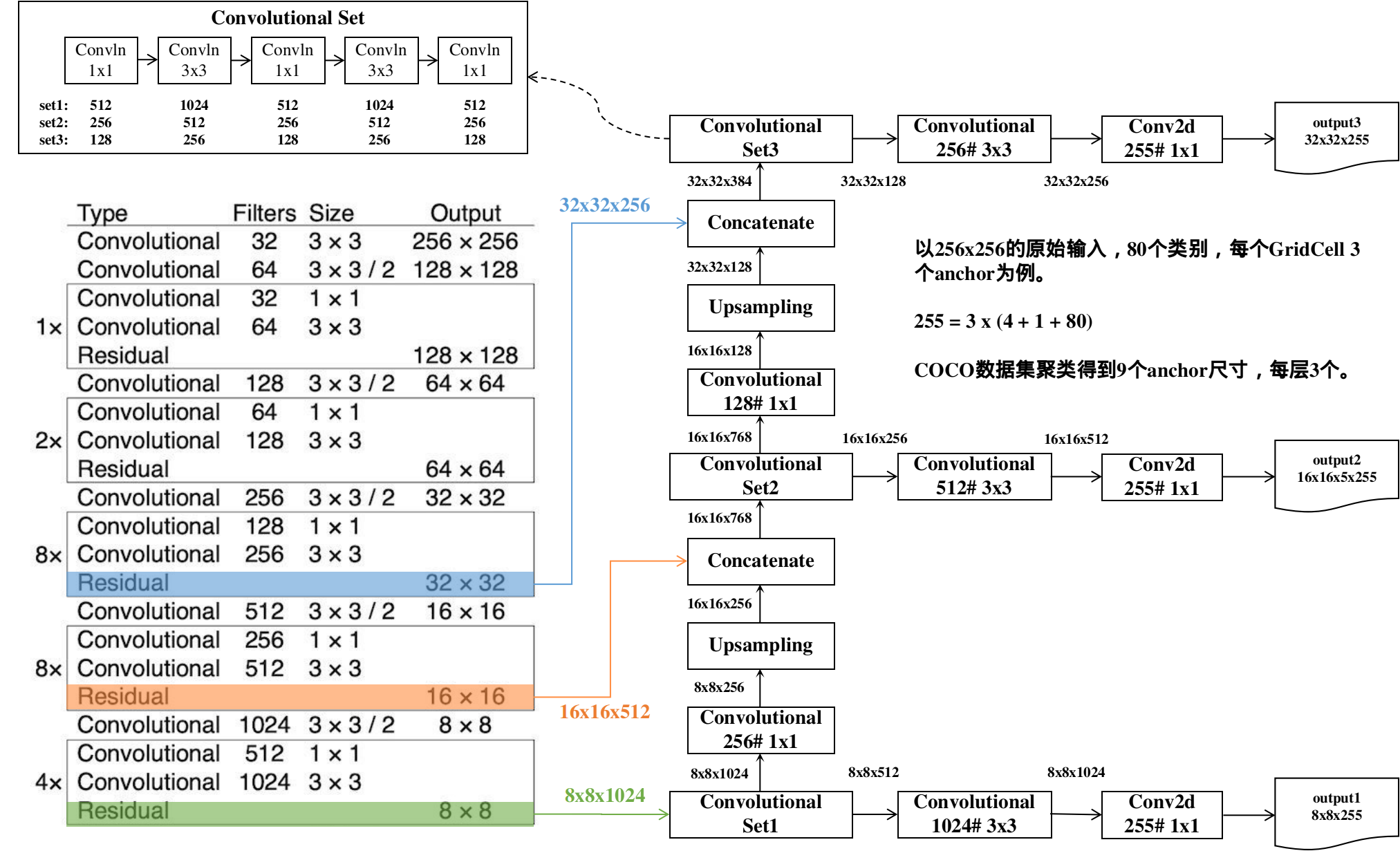
3.2 损失函数与GT&预测匹配方式
要计算损失函数,首先要解决GT信息与预测信息的匹配问题。YOLOv1的匹配方式上文已经说明了,YOLOv2的匹配方式原论文中没有明讲,但鉴于v2中一个GridCell已经预测不止一个结果向量,所以可以推断v2和v3一样,已经做了匹配方式的升级。具体是怎么做的呢?
其实还是借鉴了FasterRCNN和SSD等主流目标检测模型的做法,在一个GridCell内计算所有anchor框(而不是decode之后的预测框哦)和GT框的IOU混淆矩阵,然后利用这个混淆矩阵为每一个GTbox分配一个anchor。这一点跟FasterRCNN和SSD是不同的,虽然匹配的标准都是取最大IOU,但这两者都是AssignGTbox2Anchor,而这里是AssignAnchor2GTbox。
进一步地,如果一个anchor对于任意一个GTbox都没能取得最大IOU,那么此时根据这个anchor所能取得的最大IOU分两种情况:
- 所能取得的最大IOU小于0.5,那么这个anchor的结果向量不参与定位误差和分类误差的计算,但是参与“框的置信度”误差计算。
- 如果大于0.5,那么这个anchor的结果向量不参与任何误差的计算。
确立了匹配规则之后,即可开始计算损失。YOLOv3的损失和v1相比也略有不同,总体还是分为三部分:定位损失(对应上文的L1+L2),置信度损失(对应上文的L3+L4),分类损失(对应上文的L5)。
3.2.1 定位损失
定位损失无非xywh四项,只不过由于v3中引入了取消了wh的根号,全部采用平方误差和的形式。
其中,
也就是说中心点坐标的误差计算,并没有对GT框的xy信息完全decode,这是因为计算sigmoid的反函数有点麻烦,并且没有必要。
wh项的比对则是按照上述YOLO的encode公式对GT框的wh信息进行完全decode,然后对比decode之后的box_reg参数。即,
这样,遍历每一对GT框和anchor框求得平方误差和,最后求算数平均值即可。
3.2.2 置信度损失
v3置信度损失的计算方法由均方差调整为了交叉熵,并且有一些细节需要额外注意。
可以看到这里并不只统计正样本的置信度误差(跟v1一样,v1中也是有L3和L4两部分),这是因为按照本小节开头所描述的匹配规则,没有匹配到GTbox并且没有被丢弃的anchor的结果向量也要参与置信度损失计算。
那么问题来了,这个时候都没有配对成功,GT信息从何而来呢?原论文中的做法是令此时的GT置信度$C$为0,并且顺带着把配对成功的GT的置信度设定为1,不再计算预测框和GT框的IOU了。
也就是说对于一个未被丢弃的anchor,当它匹配上GT时,它产生的损失是$-\ln(\sigma(t_o))$,这样预测置信度越小,损失越大,这是我们希望看到的,因为此时你都匹配上GT框了,置信度还这么低是不对的。
相反,当一个未被丢弃的anchor没有匹配上GT时,它产生的损失是$-\ln(1-\sigma(t_o))$,这样预测置信度越小,损失也越小,这也是我们希望看到的,因为此时这个框的预测很失败,我们当然希望它的置信度相应地很小。
也有很多YOLOv3的实现不是简单将GT置信度设置为0和1,而是一如既往的求IOU,据说也是有效的。
3.2.3 分类损失
v3的分类损失同样由均方差调整为了交叉熵,而且是二值交叉熵:
其中,$p$是GT值,是一个one-hot向量。$\hat{p}$是结果向量中的那20位类别分数经过sigmoid之后的值。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!